Python
krótkie notatki służące pomocy w zaczęciu z programowaniem w języku Python.
- O Pythonie
- Zmienne i typy podstawowe
- Podejmowanie decyzji
- Struktury danych
- Modyfikacja zmiennej
- Pętle, moduł żółwia
- Szyfrowanie
- Pliki
- Własne funkcje
- GUI - Flet
- GUI - TkInter
- Programowanie obiektowe - klasy
- PyGameZero
- Streamlit
- API
- Zagadnienie zaawansowane
O Pythonie
Python to język programowania ogólnego zastosowania cechujący się bogactwem bibliotek (czyli mamy sporo "gotowców") i czytelną, zwięzłą składnią (dzięki czemu jest relatywnie łatwy w nauce).
Należy do języków z mechanizmem automatycznego zarządzania pamięcią (co również ułatwia naukę).
Jest językiem interpretowanym (nie wymaga kompilacji przed uruchomieniem) co ułatwia przenoszenie aplikacji w nim napisanych na różne platformy (Windows, Linux, MacOS...) kosztem wydajności.
Cechy te sprawiają, że jest to jeden z najpopularniejszych języków i często jest polecany osobom zaczynającym naukę programowania. Przyczynił się też do popularyzacji zastosowań AI i jest szeroko wykorzystywane w nauce, statystyce.
Subiektywne zestawienie zastosowań Pythona
Jak każdy inny język programowania Python ma swoje mocne i słabsze strony. Poniżej znajdziesz tabelkę z moją subiektywną oceną w jakich dziedzinach sprawdza się dobrze, średnio, słabo.
| Zastosowanie | Dobre | Średnie | Niewskazane |
|---|---|---|---|
| uczenie maszynowe / AI | x | ||
| inżynieria i analiza danych | x | ||
| backend aplikacji internetowych | x | ||
| automatyzacja (skrypty, DevOps etc.) | x | ||
| web scraping | x | ||
| aplikacje "stacjonarne" | x | ||
| aplikacje mobilne | x | x | |
| programowanie mikrokontrolerów | x | ||
| gry | x | ||
| frontend | x | ||
| aplikacje systemowe | x |
Zmienne i typy podstawowe
Deklaracja zmiennych
W Pythonie bezpiecznie jest myśleć o zmiennych jak o etykietach wskazujących nam na jakąś zawartość (formalnie przyjmujemy, że oba te elementy są częścią zmiennej - jednak wg. mnie zaproponowane podejście ułatwia na początku uniknięcie wielu błędów). Ta sama zawartość może mieć wiele etykiet (czyli kilka zmiennych może wskazywać na te same dane - warto jednak takich sytuacji unikać).
Zmienne deklarujemy wg. poniższego schematu:
nazwa_zmiennej = zawartość
Znak równości służy więc do przypisania nazwy (którą umieszczamy po lewej stronie znaku) do jakiegoś obiektu (który umieszczamy po prawej stronie znaku) np.
moj_zwierzak="pies"
W powyższym przykladzie moj_zwierzak to nazwa zmiennej (którą będziemy wykorzystywać w programie) a "pies" to zawartość.
Tworząc nazwę MUSIMY przestrzegać kilku zasad:
- nazwa nie może zawierać większości znaków specjalnych (w tym spacji - można zastąpić j ą
_) - nie może składać się z samych liczb, ani zaczynać od nich
Dobrą praktyką jest:
- używanie jedynie małych liter
- jeśli chcemy aby nazwa składała się z kilku słów oddzielamy je "podłogą" (czyli
_) - nadawanie nazw, które dobrze oddają zawartość (nie powinny jednak być przesadnie długie)
- unikanie polskich znaków
Dynamiczne typy zmiennych
Zwróć uwagę, że raz zadeklarowana zmienna MOŻE zmienić swój typ - np. coś co wskazywało na liczbę chwilę później może wskazywać na tekst. Czyli w Pythonie taka operacja wykona się poprawnie:
moja_zmienna = 1
moja_zmienna = "pies"
W wielu innych językach (tzw. statycznie typowanych) taki zapis byłby niepoprawny - jeśli raz przypisalibyśmy do zmiennej np. liczbę to przez cały cykl życia aplikacji trzeba by było się tego trzymać.
Mimo tej możliwości którą daje Python zazwyczaj dobrą praktyką jest trzymanie pod utworzoną zmienną jednego typu danych.
- służy do wyświetlania na ekranie reprezentacji obiektu (np. do wyświetlania tekstu)
- składnia wygląda następująco:
print(zawartość_do_wyświetlenia)
np.
zdanie = "To jakiś tekst"
spowoduje wyświetlenie następującej zawartości w terminalu:
To jakiś tekst
Należy pamiętać o pisaniu polecenia z małej litery - czyli print jest ok, podczas gdy np. Print nie zostanie rozpoznane (w większości języków programowania wielkość liter ma znaczenie).
Input
- służy do umożliwienia użytkownikowi wprowadzenia jakiejś zawartości
- wszystko co zostanie wprowadzone w ten sposób będzie traktowane jako tekst(!), jeśli chcemy wprowadzić z wykorzystaniem
inputliczbę musimy dokonać konwersji z tekstu na np. liczbę całkowitą, lub zmiennoprzecinkową - składnia wygląda następująco:
nazwa_zmiennej = input ("opcjonalny_komunikat dla użytkownika")
np.
imie_gracza = input("Wprowadz imię: ")
Typy podstawowe
Typy określają wspólne cechy obiektów, metody z nimi związane. Dzięki nim programiści wiedzą jakie operacje na nich są dozwolone (a jakie nie). Są więc bardzo przydatnym środkiem komunikacji przy pisaniu aplikacji.
Python obsługuje następujące typy podstawowe:
Liczby całkowite (integer)
Liczy naturalne (1, 2, 3, 4...) i przeciwne do nich (-1, -2, -3) oraz zero.
Przypisując do zmiennej liczbę całkowitą po prostu podajemy ją po znaku równości np.
moja_liczba = 12
Liczby zmiennoprzecinkowe (float)
Liczby zapisane z "częścią ułamkową". Ważne - część ułamkowa zapisana jest po KROPCE, nie po przecinku.
moja_liczba = 22.15
Ciągi znaków (string)
Seria znaków zapisana między cudzysłowami pojedynczymi, lub podwójnymi (nie można ich jednak mieszać!) np.
moj_tekst = "To tylko tekst."
Wartości logiczne (bool)
Wartości prawda / fałsz zapisane jako True / False (istotna jest wielkość znaków!).
np.
gra_gotowa = True
Podstawowe operacje
Podstawowe operatory to:
dodawanie +
odejmowanie -
mnożenie *
dzielenie /
modulo % (reszta z dzielenia)
Można ich używać na:
| integer | float | string | bool | |
|---|---|---|---|---|
+ |
tak | tak | tak | tak |
- |
tak | tak | nie | tak |
* |
tak | tak | tak, ale... | tak |
/ |
tak | tak | nie | - |
% |
tak | tak | nie | - |
W przypadku ciągu znaków (string) możemy wykonać operację mnożenia przez liczbę - powtórzy nam to dany tekst wskazaną ilość razy. Nie można jednak mnożyć ciągu znaków przez ciąg znaków.
Wartości logiczne True / False są równoważne 1 i 0 - stąd też da się wykonać operacje dzielenia, czy modulo... z założeniem, że nie dzielimy przez 0 ;) .
Odnośniki
„3.12.5 Documentation”. Dostęp 18 sierpień 2024. https://docs.python.org/3/.
Viafore, Patrick. Robust Python: write clean and maintainable code. First edition. Beijing [China]; Boston [MA]: O’Reilly, 2021.
„Zmienna (informatyka)”. W Wikipedia, wolna encyklopedia, 15 kwiecień 2024. https://pl.wikipedia.org/w/index.php?title=Zmienna_(informatyka)&oldid=73515366.
„Magic Python: Mutable vs Immutable and How To Copy Objects”. Dostęp 18 sierpień 2024 https://alexkataev.medium.com/magic-python-mutable-vs-immutable-and-how-to-copy-objects-908bffb811fa
Podejmowanie decyzji
Porównania
Żebyśmy mogli podjąć w programie jakąś decyzję musimy najpierw sformułować pytanie na które da się jednoznacznie odpowiedzieć tak/nie (prawda / fałsz) .
Najprostszym podejściem do tego jest wykonanie jakiegoś porównania np. czy 12 jest większe od 6.
Podstawowe porównania
| Operator | Pytanie | Przykład |
|---|---|---|
== |
równe? | x == y |
!= |
nierówne? | x != y |
> |
większe? | x > y |
>= |
większe lub równe? | x >= y |
< |
mniejsze? | x < y |
<= |
mniejsze lub równe? | x <= y |
W Pythonie jest podwójny znak równości (==) służy do porównania czy dane wartości są równe, podczas gdy pojedynczy = służy do przypisania wartości.
Porównania tekstów
O dziwo w Pythonie porównanie tekstów są dozwolone np.
"pies" > "kot"
Takie porównanie zwróci nam wartość True.
Jak Python doszedł do takiego wniosku? Każdy znak jest jakąś liczbą w ściśle określonej tablicy znaków (w tym wypadku unicode). Python porównuje numer danej litery dla każdego znaku w tekście i na tej podstawie podejmuje decyzję.
Warunki i bloki kodu
Mając przygotowane pytanie na które da się odpowiedzieć tak/nie, prawda/fałsz możemy wykonać jakąś akcję wg schematu:
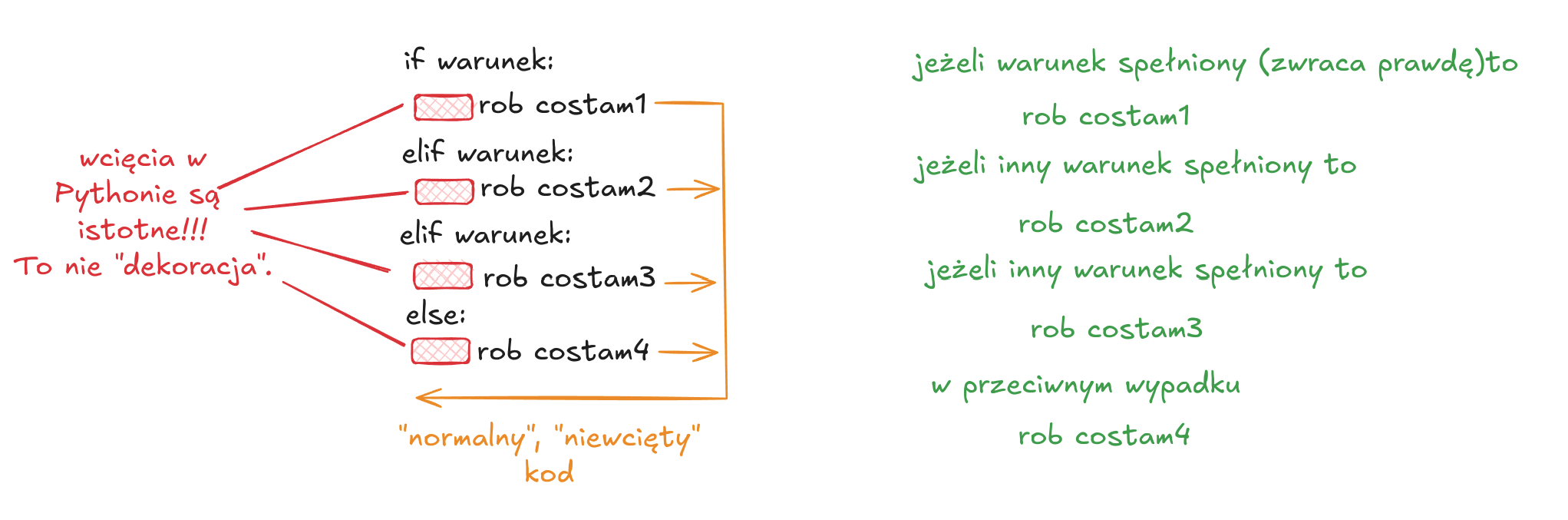
A = 12
B = 6
jeżeli A > B:
wykonaj coś1
a jeżeli A == B:
wykonaj coś2
w przeciwnym wypadku: (jeśli żaden inny warunek nie został spełniony)
wykonaj coś3
Tłumacząc to na Pythona wygląda to tak:
# to pseudokod - nie zadziała bo nie poinformowaliśmy Pythona co oznacza zrob_cos :D
A = 12
B = 6
if A > B:
zrob_cos(1)
elif A==B:
zrob_cos(2)
else:
zrob_cos(3)
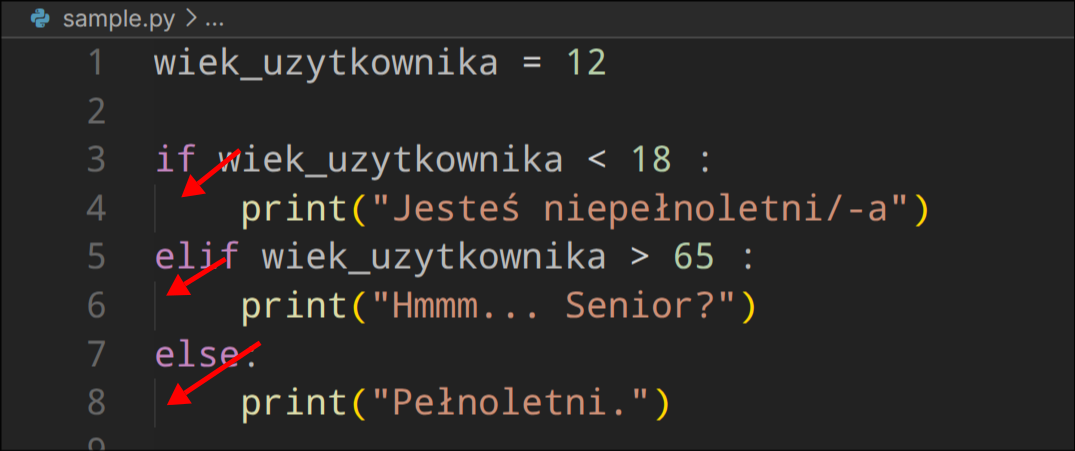
Należy pamiętać o wcięciach(!) - decydują one o tym co Python wykona po podjęciu decyzji np. w powyższym przykładzie jeśli A jest większe od B to uruchomi się jedynie funkcja (fikcyjna) zrob_cos(1).
np.
wiek_uzytkownika = 12
if wiek_uzytkownika < 18 :
print("Jesteś niepełnoletni/-a")
elif wiek_uzytkownika > 65 :
print("Hmmm... Senior?")
else:
print("Pełnoletni.")
Czemu warto korzystać z elif
Teoretycznie można by było w powyższym przykładzie użyć tylko i wyłącznie if - użytkownik programu nie zauważyłby raczej różnicy.
Dla komputera jednak różnica jest spora - używając tylko if wykonałby każde z porównań niezależnie od wyniku poprzedniego.
Jeśli korzystamy z elif / else porównania wykonują się do momentu uzyskania w którymś odpowiedzi Prawda (True) - pozostałe wtedy są pomijane. Dzięki temu minimalizujemy ilość niepotrzebnie wykonywanych operacji.
Korzystając z if bez elif należy też uważać na ew. dodanie sekcji else - w takiej sytuacji else będzie się odnosic wyłącznie(!) do ostatniego warunku (ostatniego if-a).
Stąd też jeśli wykonujemy jakieś porównania, które są z sobą powiązane (zależą od siebie) należy korzystać z elif i else.
Wcięcia w edytorach kodu
Edytoru kodu starają się pomóc użytkownikom z wcięciami - w oczywistych miejscach od razu je dla nas robią. Oprócz tego w większości z nich są one oznaczana pionową linią:
Struktury danych
- służą do organizowania i przechowywania danych
- jest ich wiele rodzajów. Wybierane są pod kątem konkretnego zastosowania - czy do danego celu dana struktura będzie efektywna i czy umożliwi korzystanie z danych w sposób nie zaskakujący odbiorców (programistów)
- sama w sobie struktura niesie ze sobą znaczenie i spełnia pewne oczekiwania np. wybierając w Pythonie listę programista wie, że może ją modyfikować i że powiązane są z nią pewne metody służące do jej obsługi
Listy i krotki
W obu wypadkach:
- każdy element ma swój indeks umożliwiający jego szybkie odnalezienie
- obie mogą posiadać duplikaty
- w obu wypadkach można się przemieszczać (iterate) po ich elementach
ALE...
Listy (list)
- są modyfikowalne (mutable) tzn. można do nich dodawać / odejmować nowe elementy
- bardzo często przemieszczamy się w ich wypadku po elementach
- raczej unika się sięgania po elementy umieszczone gdzieś w środku list
- dobrą analogią mogą być książki na półce
- deklaruje się je poprzez użycie nawiasów kwadratowych
[]np.
moje_ksiazki = ["Blade Runner", "Hobbit", "Unicorn Project"]
Krotki (tuple)
- są niemodyfikowalne (immutable)
- ponieważ ich długość jest stała częściej sięgamy po elementy znajdujące się gdzieś głęboko w nich
- dobrym przykładem mogą być np. kategorie w menu restauracji
- deklaruje się je poprzez użycie nawiasów okrągłych
()np.
menu_kategorie = ("przystawki", "zupy", "desery")
Indeksy
Chcąc "wyciągnąć" konkretny element będący ich częścią wpisujemy identyfikator w nawiasach kwadratowych po nazwie zmiennej .
nazwa_zmiennej[indeks] np.
moja_lista = ["cos1", "cos2", "cos3", "cos4" ]
print(moja_lista[2])
WAŻNE!!! Indeksy są liczone od 0 nie od 1 . Stąd też pierwszy element na powyższej liście ma indeks 0, ostatni 3.
Możliwe jest też sięgnięcie "wstecz" np. ostatni element można wskazać przez użycie indeksu -1.
"Cięcie" list i krotek
Chcąc wyświetlić zakres elementów listy / krotki należy wpisać w nawiasie kwadratowym element startowy i element końcowy oddzielone dwukropkiem.
moja_zmienna[start:koniec]
np.
print(moja_lista[1:3])
Jeśli jest potrzeba "przeskakiwania niektórych wartości to można ten schemat rozszerzyć:
moja_lista[start:koniec:krok]
Należy to czytać - "wybierz elementy z moja_lista, zaczynając od start, zatrzymując się PRZED koniec (czyli element o tym indeksie nie wejdzie w wybrany zakres) i przeskakując co skok.
Co ciekawe przy tych "wycinkach" (slices) list/krotek podanie indeksów poza zakresem etc NIE spowoduje błędu - stworzy po prostu pustą listę/krotkę.
lista_a = [0, 1, 2, 3]
wycinek = lista_a[8:12] # to nie spowoduje błędu!
print(wycinek)
# wynikiem będzie:
# []
# ... czyli powstała pusta lista
Metody dla list i krotek
Metody to specjalne funkcje "wbudowane" w dany obiekt. Wywołuje się je poprzez wpisanie nazwy zmiennej, postawienie kropki i wstawienie parametrów do metody w nawiasach okrągłych (jeśli nie przekazujemy żadnych zostawiamy same nawiasy okrągłe).
| krotka | lista | opis |
|---|---|---|
| .count() | .count() | zlicza ilość wystąpień przekazanego parametru |
| .index() | .index() | podaje pierwszy indeks pod którym jest przekazana wartość |
| .append() | dodaj argument do listy | |
| .pop() | usuń element o podanym indeksie z listy(lub ostatni element) | |
| .sort() | sortuje elementy | |
| .copy() | zwraca kopię obiektu |
Słowniki i zbiory
Zarówno słowniki jak i zbiory przechowują "klucze", które nie mogą się powtarzać. Jednak w przypadku słowników z kluczem jest powiązana wartość.
Klucze muszą być wartością na której da się wykonać tzw. funkcję skrótu (są "hashable"). W tym wypadku chodzi o to, że muszą to być obiekty, które nie są modyfikowalne (np. ciągi znaków, liczby).
Słowniki (dict)
Umożliwiają szybkie odnalezienie jakiejś zawartości z pomocą wartości klucza przypisanego do niej.
Deklarujemy je poprzez użycie nawiasów klamrowych, a w nich pary klucz, wartość rozdzielonych dwukropkiem.
**moj_slownik={klucz:wartość} **
np.
menu ={
"zupa" : "ogórkowa",
"lody" : "waniliowe",
"sok" : "pomarańczowy"
}
Chcąc wyświetlić wartość przechowywaną pod konkretnym kluczem działamy podobnie jak z listą.
Różnica polega na tym, że w nawiasach kwadratowych podajemy nie indeks, tylko klucz np.
print(menu["zupa"])
Jeśli kluczem jest np. jakiś tekst będący nazwą potrawy a wartością lista zawierająca jej składniki to trzymamy się tego przez cały słownik.
Przy konstruowaniu słownika warto być konsekwentnym - nie wrzucamy jako kolejnego elementu np. klucza z jakąś liczbą (niech to będzie chociażby numer strony naszej ulubionej książki kucharskiej) zestawionego z krotką przechowującą kaloryczność składników jako wartość.
Zwracajmy też uwagę na to czy faktycznie w naszym programie korzystamy z tych słownikowych kluczy - jeśli nie, to jest spora szansa, że powinniśmy skorzystać z innej struktury danych.
Słowniki - dodawanie elementów
Wystarczy przypisać jakąś wartość pod dany klucz - nie potrzeba używać żadnej specjalnej mentody. Jeśli dany klucz istnieje to wartość przechowywana pod nim zostanie podmieniona, jeśli nie to do słownika zostanie dodana nowa para klucz:wartość.
nazwa_zmiennej[klucz] = wartosc
np. żeby dodać do słownika menu nowy klucz "przystawki" z jakąś wartością można:
menu ={
"zupa" : "ogórkowa",
"lody" : "waniliowe",
"sok" : "pomarańczowy"
}
menu["przystawki"] = "sałatka grecka"
Słowniki - usuwanie elementów
Żeby usunąć element ze słownika można skorzystać z metody .pop(), podając w nawiasie okrągłym klucz elementu do usunięcia.
Np. chcąc usunąć parę "zupa" : "ogórkowa" z słownika menu wyglądałoby to tak:
menu.pop("zupa")
Słowniki - metody
| słownik | opis |
|---|---|
| .keys() | zwraca listę kluczy słownika |
| .values() | zwraca listę wartości słownika |
| .pop() | usuwa element o podanym kluczu |
| .items() | zwraca listę krotek dla każdej pary klucz:wartość |
| .get() | zwraca wartość dla danego klucza |
Zbiory (set)
Wyglądają podobnie do listy. Mają jednak jedną cenną cechę:
nie posiadają duplikatów wartości.
Czyli jeśli dwa razy spróbujemy do zbioru dodać np. słowo "kot" to ten drugi wpis zostanie usunięty.
Nie mają też indeksów (!).
Bezpiecznie jest myśleć o nich jako o takich dziwnych słownikach, które mają jedynie klucze.
Pewnie dlatego też, podobnie jak słowniki, deklaruje się je z użyciem nawiasów klamrowych:
moj_zbior={unikat1, unikat2, unikat3}
Właśnie ten brak powtórzeń jest często wykorzystywany - np. zamieniamy listę na zbiór żeby pozbyć się duplikatów.
Zamiana listy na zbiór... i z powrotem :)
ksiazki = ["Endymion", "Hobbit", "Fundacja", "Endymion"]
zbior_ksiazek = set(ksiazki)
ksiazki_bez_powtorzen = list(zbior_ksiazek)
Które typy są modyfikowalne (mutable)?
| typ | modyfikowalny | niemodyfikowalny |
|---|---|---|
| liczba całk. | tak | |
| liczba zmiennop. | tak | |
| wart.log | tak | |
| ciąg znaków | tak | |
| krotka | tak | |
| lista | tak | |
| słownik | tak | |
| zbiór | tak |
Odnośniki
„3.12.5 Documentation”. Dostęp 18 sierpień 2024. https://docs.python.org/3/.
Viafore, Patrick. Robust Python: write clean and maintainable code. First edition. Beijing [China]; Boston [MA]: O’Reilly, 2021.
Modyfikacja zmiennej
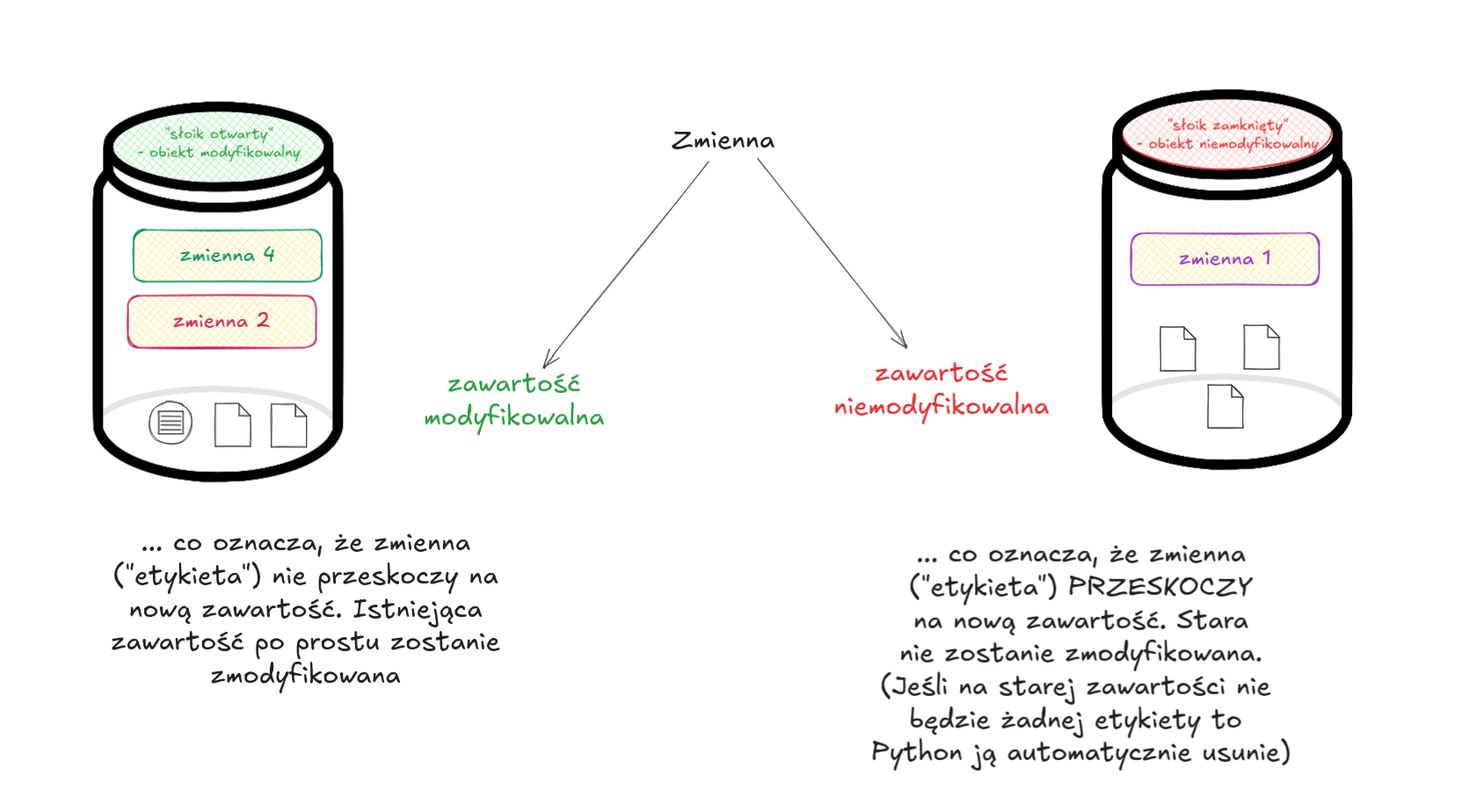
Niektóre zmienne przekazywane są po wartości - co oznacza, że wartość jednej zmiennej jest KOPIOWANA do drugiej. Dotyczy to wszystkich typów, które są niemodyfikowalne - czyli np. liczb, ciągu znaków (teksty - string), wartości logicznych, krotek.
np.
a = 4 # liczba jest "niemodyfikowalna" sama z siebie
b = a # do zmiennej b jest kopiowana 4 przechowywana pod a
b = b + 2 # do wartości przechowywanej pod b dodawane jest 2
print(a)
print(b)
# wynikiem jest:
# 4
# 6
# wynika to z tego, że b miało wartość SKOPIOWANĄ z a
W Pythonie istnieją też typy, które podlegają modyfikacji - np. listy czy słowniki. W ich wypadku to przekazanie nie robi kopii - przekazywana jest tzw. referencja do obiektu (okropny anglicyzm). Czyli zamiast kopiować wartość przekazywany jest wskaźnik informujący gdzie w pamięci komputera przechowywana jest interesująca nas wartość.
a = [4,2] # liczba jest "niemodyfikowalna" sama z siebie
b = a # zmienna b przechowuje ten sam wskaźnik do obiektu co a
b.pop() # z listy na którą wskazuje b usuwana jest ostatnia wartość
print(a)
print(b)
# wynikiem jest:
# [4]
# [4]
# wynika to z tego, że b i a wskazują na tę samą listę (nie jest robiona kopia)
Skopiowanie wartości
W przypadku gdy mamy do czynienia z obiektem niemodyfikowalnym (np. krotką) jedyne co Python może zrobić to "przekleić" naszą etykietę (zmienną) na nowy obiekt. Jeśli ten pierwotny nie będzie miał na sobie innej etykietki (nie wskazuje na niego inna zmienna) to zostanie on automatycznie usunięty (przez tzw. garbage collector).
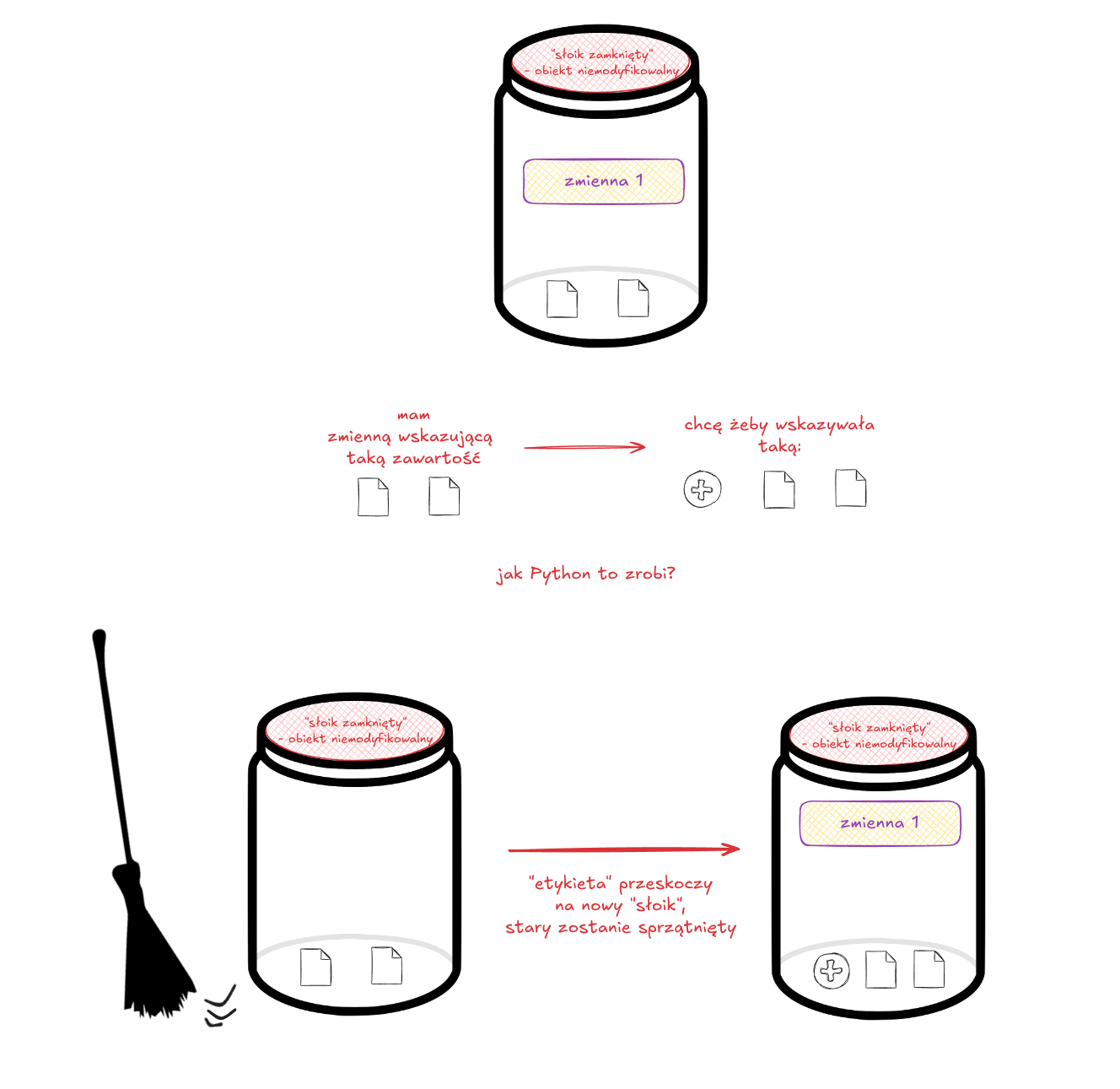
Zmiana zawartości
W przypadku gdy obiekt jest modyfikowalny (np. lista) i dołożymy do niej kolejny element zmienna nie będzie musiała przeskoczyć na nowy obiekt z nową zawartością - po prostu zostanie dodany nowy element (zmieni się zawartość obiektu, etykieta będzie wskazywać ten sam obiekt).
... a czemu to istotne?
Powody są co najmniej dwa:
- Należy pamiętać, że gdy zmieniamy jakiś obiekt modyfikowalny na który wskazuje kilka zmiennych to zmienimy wartości dla każdej z nich.
- Tworzenie obiektów (rezerwowanie miejsca w pamięci dla nich) to proces względnie czasochłonny - stąd też proces kopiowania całego obiektu i dodawania do niego jakiegoś dodatkowego elementu (czyli wariant z obiektem niemodyfikowalnym) może spowolnić działanie tworzonej aplikacji.
-> stąd też tak istotne jest świadome dobieranie struktur danych :) .
Co jest modyfikowalne, a co nie?
| typ | modyfikowalny | niemodyfikowalny |
|---|---|---|
| liczba całk. | tak | |
| liczba zmiennop. | tak | |
| wart.log | tak | |
| ciąg znaków | tak | |
| krotka | tak | |
| lista | tak | |
| słownik | tak | |
| zbiór | tak |
Pętle, moduł żółwia
Do wykonywania powtarzalnych czynności używamy w programowaniu pętli.
Pętla for
Wykonuje blok kodu tyle razy ile mamy jakiś elementów w sekwencji (np. tyle razy ile mamy liter w wyrazie, elementów w liście) / pozostałych obiektach iterowalnych
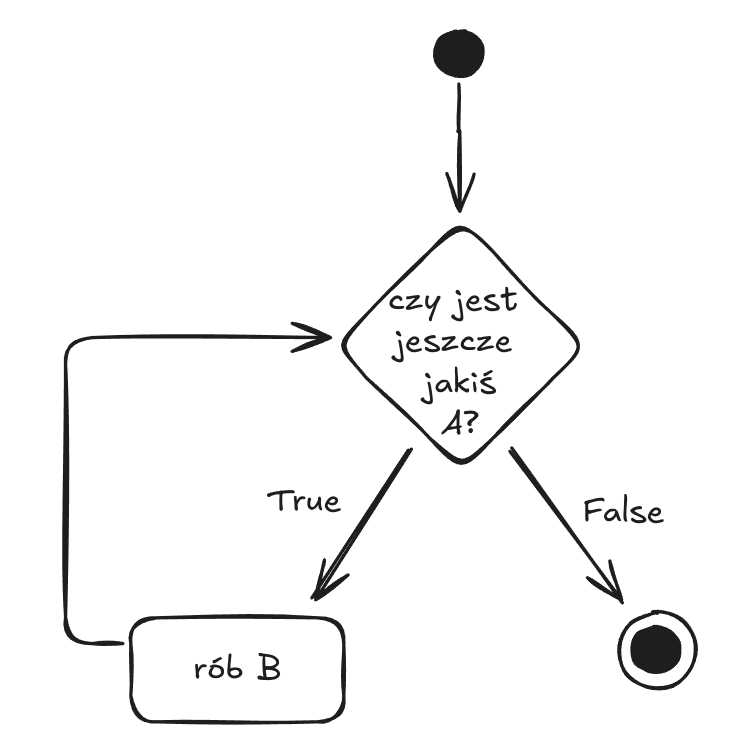
np.
for litera in "Robisz.to":
print(litera)
for element in ["a", "b", "c"]:
print(element)
Na początku najważniejsze (i prostsze do zrozumienia) jest przyjęcie, że obiektem dla pętli for są sekwencje / inne iterowalne elementy - ciągi znaków, listy, krotki, range.
Nie ma obowiązku wykorzystywania elementu sekwencji w powtarzalnym bloku. Jeśli używamy go jedynie do przemieszczania się po sekwencji to dobrą praktyką jest nazwanie go "_" (czyli użycie znaku podłogi).
Ogólny schemat korzystania z tej pętli:
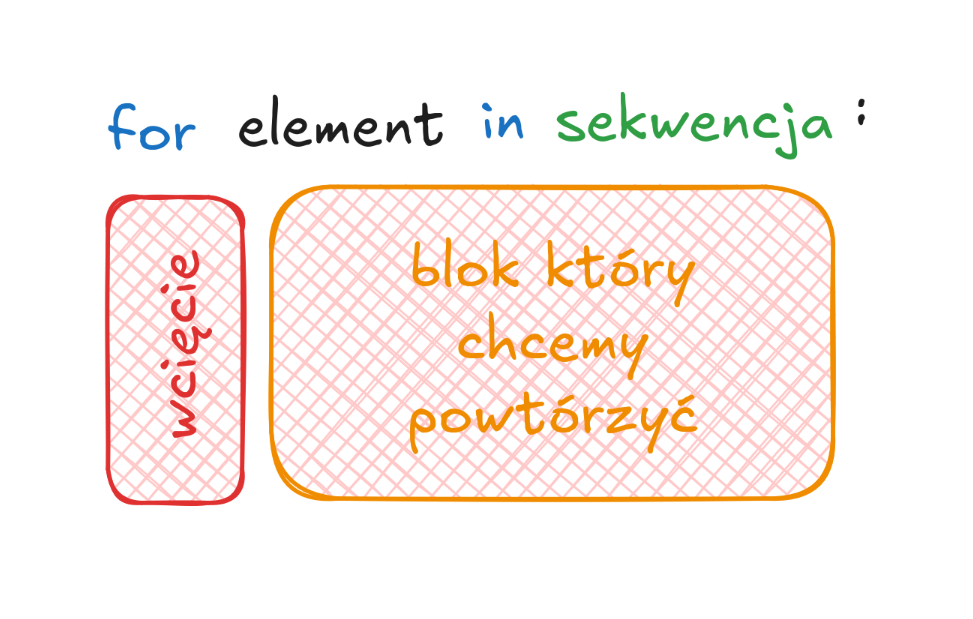
Na powyższym obrazku słowo "sekwencja" jest użyte w potocznym rozumieniu. Tak jak wspomniano wyżej chodzi o każdy iterowalny element. Na start można jednak nie zawracać sobie głowy tymi subtelnościami - dla zainterowanych link w odnośnikach.
Pętla while
"... wykonuj tak długo aż"
- pętla ta wykonuje się tak długo jak jakiś warunek jest spełniony
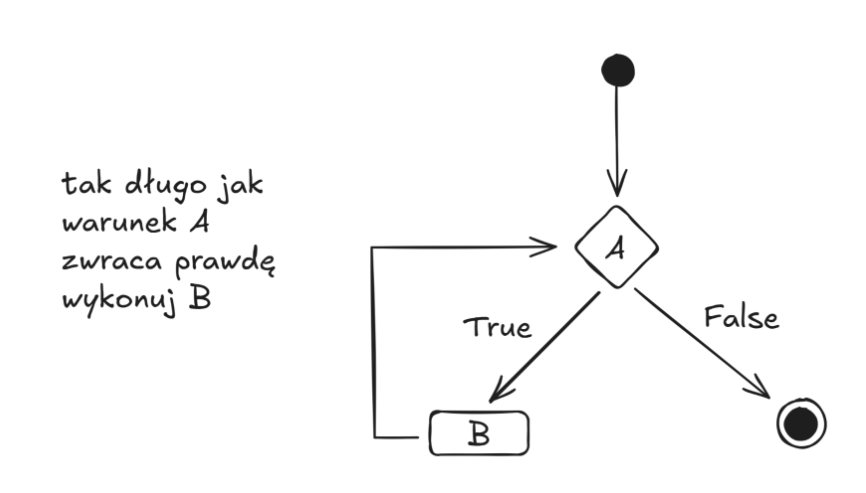
np.
i = 0
while i < 10:
print(i)
i += 1
Przy każdym "obrocie" pętli zwiększamy "i" o 1, gdy osiągnie 10 warunek "i < 10" zwróci False i pętla przestanie się wykonywać.
Break
Jeśli chcemy wyjść z pętli wcześniej (w przypadku for zanim dojdziemy do ostatniego elementu, w przypadku while zanim warunek zwróci False) możemy skorzystać z break.
i = 0
while True:
if i < 10:
break
print(i)
i += 1
Funkcja range
Jeśli nie mamy jakiejś gotowej sekwencji z odpowiednią ilością elementów to z pomocą może przyjść nam funkcja range.
W najprostszej postaci konstruujemy ją tak:
range(ilośc_elementów)
np. chcąc wyświetlić napis "Hej" 3 razy możemy zrobić to tak:
for _ in range(3):
print(Hej)
Jeśli jednak potrzebujemy jakiegoś konkretnego zakresu (np. od 10 do 20 etc) i o konkretnym kroku (czyli elementy zwiększają się o konkretną wartość) można skorzystać z dodatkowych parametrów:
range(start, stop, krok)
Importowanie bibliotek
Jeśli problem, który staramy się rozwiązać nie jest trywialny dobrym pomysłem może być wykorzystanie kodu napisanego przez kogoś innego.
Python dysponuje szeroką gamą bibliotek dostępnych za darmo. Całkiem pokaźna ich ilość jest instalowana razem z Pythonem.
Jeśli potrzebujemy jakiejś zewnętrznej (np. znalezionej na www.pypi.org ) możemy ją zainstalować poprzez wykonanie w terminalu:
pip3 install nazwa_bibilioteki
Aby wykorzystać zainstalowaną bibliotekę w pliku z programem nad którym się pracuje należy na początku zaimportować ją poprzez:
import nazwa_biblioteki
np.
import turtle
Jeśli jest potrzeba zaktualizowania biblioteki do najnowszej wersji można:
pip3 install -U <NAZWA_BIBLIOTEKI>
Moduł Turtle
Służy do rysowania z pomocą kodu. Idealnie nadaje się do ćwiczeń pętli - od razu widać co się dzieje, tym samym łatwiej diagnozować błędy.
Importuje się go poprzez:
import turtle
Przygotowanie programu dla "żółwia"
Po zaimportowaniu biblioteki należy stworzyć "żółwia" i przestrzeń po której będzie się poruszał:
zolwik = turtle.Turtle
Z kolei pod koniec naszego kodu (po tym jak już skończymy rysować) powinniśmy dodać:
turtle.exitonclick()
- to spowoduje, że okno z programem nie zamknie się natychmiast po tym jak żółwik skończy pracę
Podstawowe metody
Wykonujemy je na obiekcie Turtle (ja zazwyczaj nazywam go zolwik).
.forward(odległość) - przesuwa żółwia do przodu
.left(kąt) - żółwik skręca w lewo o podany kąt
.right(kąt) - skręca w prawo o podany kąt
.circle(promień) - rysuje okrąg o podanym promieniu
.penup() - żółwik przemieszczając się przestanie zostawiać ślad
.pendown() - ponownie zacznie rysować
Turtle - struktura programu
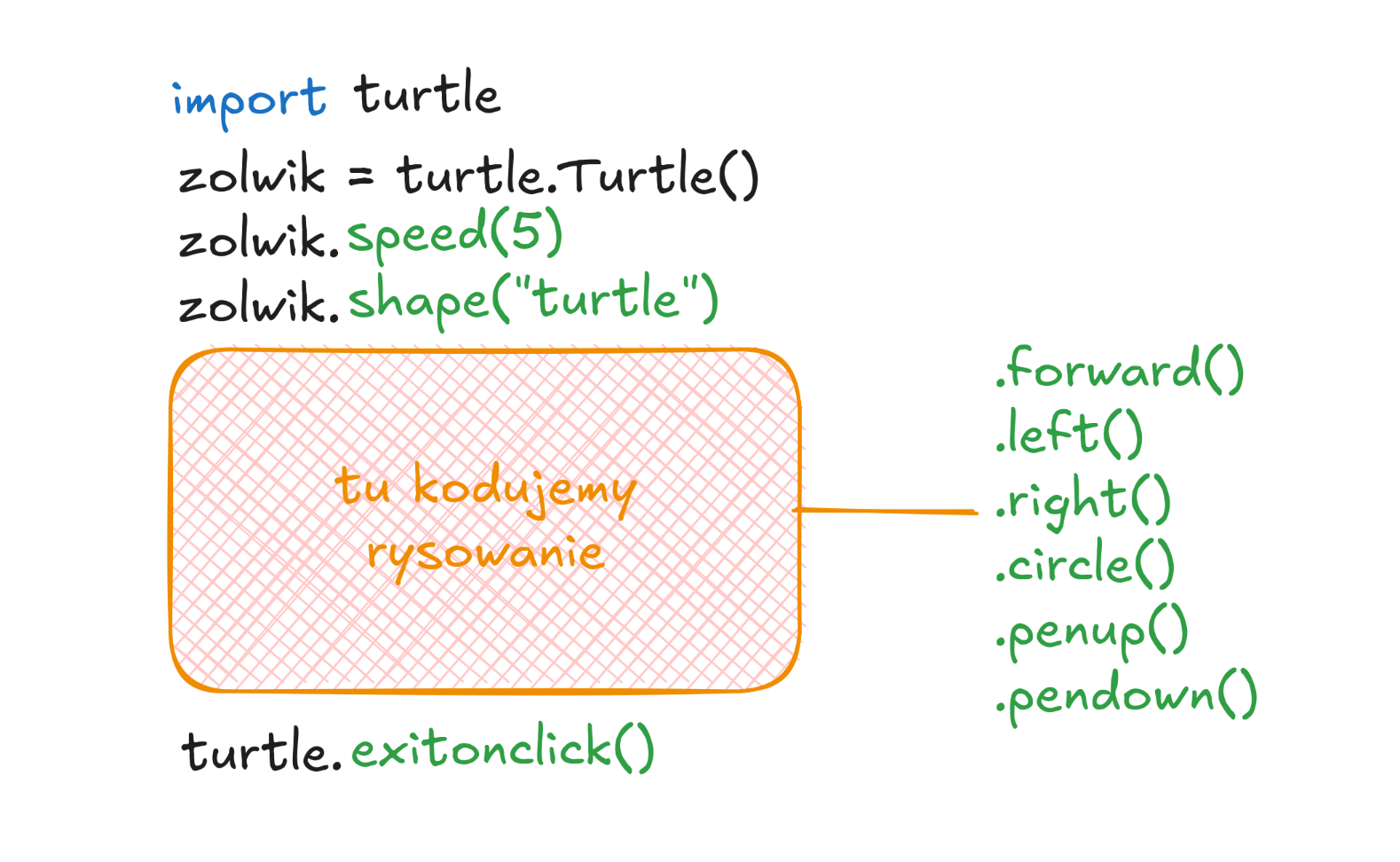
Odnośniki
„3.12.5 Documentation”. Dostęp 18 sierpień 2024. https://docs.python.org/3/.
Bunn, Tristan. Learn Python visually: creative coding with processing.py. San Francisco, CA: No Starch Press Inc, 2021.
Gruppetta, Stephen. „Iterable: Python’s Stepping Stones”, 22 czerwiec 2024. https://www.thepythoncodingstack.com/p/python-iterable-data-structures.
„Python and Turtle – Python, Turtle, Projects, Learn”. Dostęp 11 sierpień 2024. https://pythonturtle.academy/.
Szyfrowanie
Szyfrowanie
Sposób na zakodowanie danych w taki sposób, aby stały się nieczytelne. Proces ten jest jednak odwracalny. Metoda ta służy m. in. do poufnego przekazywania informacji.

Algorytmy szyfrujące
Algorytm szyfrujący to sposób w jaki zamieniamy dane na nieczytelne. Jest wiele sposobów na szyfrowanie - czyli jest wiele algorytmów.
Jeśli chodzi o kategorie do których się je da zaliczyć w tej chwili najpopularniejszy podział to podział na szyfrowanie symetryczne i asymetryczne.
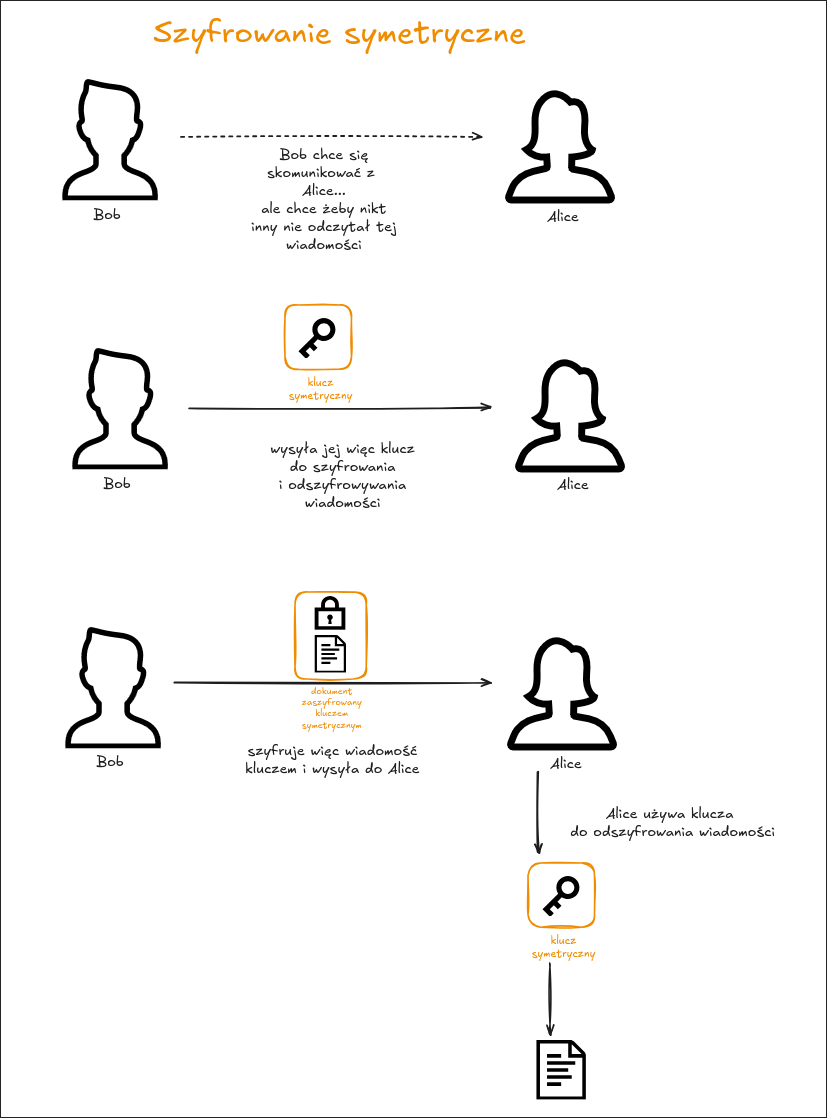
Szyfrowanie symetryczne.
- ten sam klucz jest wykorzystywany do szyfrowania i deszyfrowania danych.
Czyli obie strony (nadawca i odbiorca wiadomości) dzielą się tym samym sposobem ("hasłem" / "kluczem") umożliwiającym zakodowanie i odkodowanie wiadomości.
Pojawia się więc problem - jak przekazać bezpiecznie ten klucz? Zwłaszcza w sytuacji gdy nadawca i odbiorca nie mogą się jakoś "spotkać" w bezpiecznym miejscu, żeby podzielić się tym kluczem - np. jedna strona jest gdzieś w Polsce a druga np. w Brazylii.
Mimo tego problemu szyfrowanie tego rodzaju jest stosowane m.in. ze względu na szybkość (sprawnie działa nawet na urządzeniach o bardzo ograniczonych zasobach).
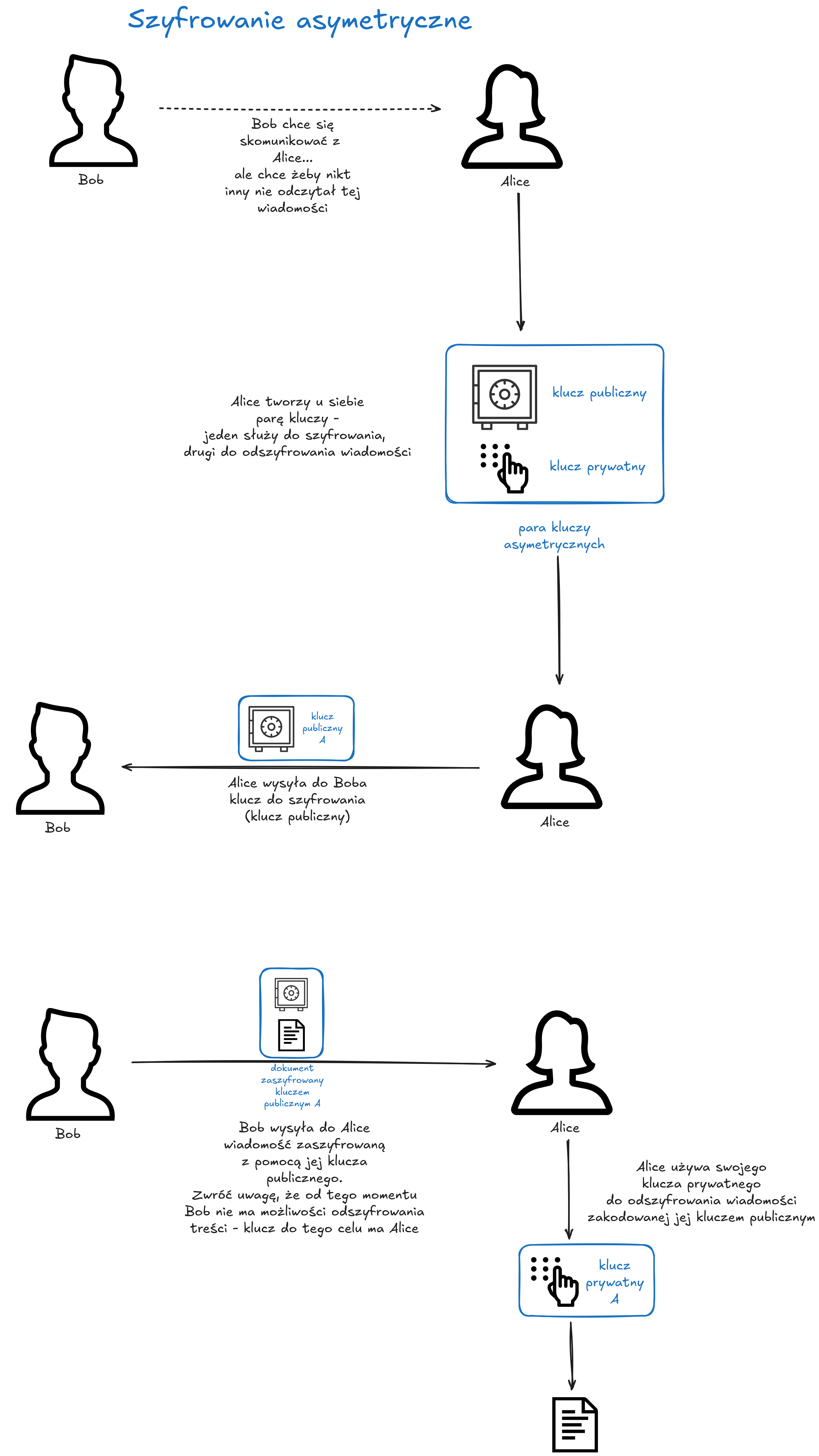
Szyfrowanie asymetryczne
- wykorzystuje dwa oddzielne klucze, jeden służy do szyfrowania danych, drugi do odszyfrowania
Ja lubię myśleć o tym w ten sposób - mamy kłódkę i klucz. Kłódkę udostępniamy publicznie, każdy może sobie ją pobrać i zaszyfrować dane z jej pomocą. My jednak mamy klucz, którym się nie dzielimy - to nasz sekret (klucz prywatny). Tylko z jego pomocą można "otworzyć" (odszyfrować) dane zaszyfrowane z pomocą "kłódki".
Dzięki temu pozbywamy się problemu z przekazaniem sposobu odszyfrowania wiadomości. De facto nie robimy tego - przekazujemy jedynie sposób na zakodowanie.
Jeśli komunikacja ma zachodzić dwukierunkowo obie strony wysyłają sobie nawzajem "kłódki" (tzw. klucze publiczne).
Ta metoda ma jednak dość poważną wadę - dużo bardziej niż algorytmy symetryczne obciąża nasze komputery.
Zwróćcie jednak uwagę, że możemy wykorzystać wolne szyfrowanie asymetryczne, żeby podzielić się z kimś szybkim kluczem symetrycznym ;) .
Funkcja skrótu (hash)
Nie należy mylić szyfrowania z hashowaniem. Funkcja skrótu tworzy nam "bełkot" na podstawie jakiś danych wejściowych. Proces ten jest (a właściwie powinien być) NIEODWRACALNY.
Jednak zawsze jesteśmy w stanie stwierdzić, że dany hash powstał na podstawie konkretnych danych wejściowych. W najprostszej postaci - te same dane wejściowe zawsze dadzą nam ten sam hash.
Co może wydawać się dziwne - po co nam coś takiego?
To super przydatne narzędzie. Umożliwia np. bezpieczne przechowywanie haseł w bazach danych. Nie przechowujemy de facto haseł tylko ich hashe - przez co w przypadku wycieku strona atakująca nie dostaje haseł.
Wykorzystując hashe jesteśmy w stanie stwierdzić czy dany pliki / wiadomości zostały zmodyfikowane - bo zmodyfikowane dane dadzą inny hash.
Programy antywirusowe nie muszą przechowywać kodu całego wirusa, żeby go namierzyć - wystarczy, że mają jego hash i szukają jego wystąpień.
Słowniki i zbiory korzystają z funkcji skrótu do wskazania miejsca gdzie można znaleźć nasze dane (to dzięki temu słowniki są szybsze od list przy dużej ilości elementów).
Szyfr Cezara
To jedna z najprostszych technik szyfrowania - do tego idealnie nadająca się do przećwiczenia pętli.
Polega ona na podmianie każdej litery tekstu jawnego (niezaszyfrowanego) inną, oddaloną o stałą liczbę pozycji w alfabecie. Liczba ta staje się kluczem do wiadomości.
np.
Alfabet: AĄBCĆDEĘFGHIJKLŁMNŃOÓPRSŚTUWYZŹŻ
Chcemy zaszyfrować imię ADA. Jako klucz przyjmijmy 3 - co oznacza, że każdą literę podmieniamy na odpowiednik po prawej stronie oddalony o 3 pozycje.
Czyli dla litery A będzie to C. Stąd też całość będzie wyglądała następująco:
Wiadomość: ADA
Klucz: 3
Zaszyfrowana: CFC
Co robić w przypadku wyjścia poza naszą tablicę znaków? Jak znowu przeskoczyć na początek?
Z pomocą przyjdzie nam modulo. Aby z jego pomocą wskazać indeks zaszyfrowanego znaku w naszym alfabecie możemy skorzystać z formuły:
indekszaszyfrowany = (indeksznaku + klucz) % len(ZNAKI)
Odnośniki
„3.12.5 Documentation”. Dostęp 18 sierpień 2024. https://docs.python.org/3/.
Pengelly, James, i Gareth Marchant. The Official CompTIA Security+ Student Guide (Exam SY0-701). CompTIA, Inc, 2023.
„Szyfr Cezara”. W Wikipedia, wolna encyklopedia, 13 czerwiec 2024. https://pl.wikipedia.org/w/index.php?title=Szyfr_Cezara&oldid=74000247.
Pliki
Tworzenie nowego folderu pod projekt
-
Uruchom menadżer plików

-
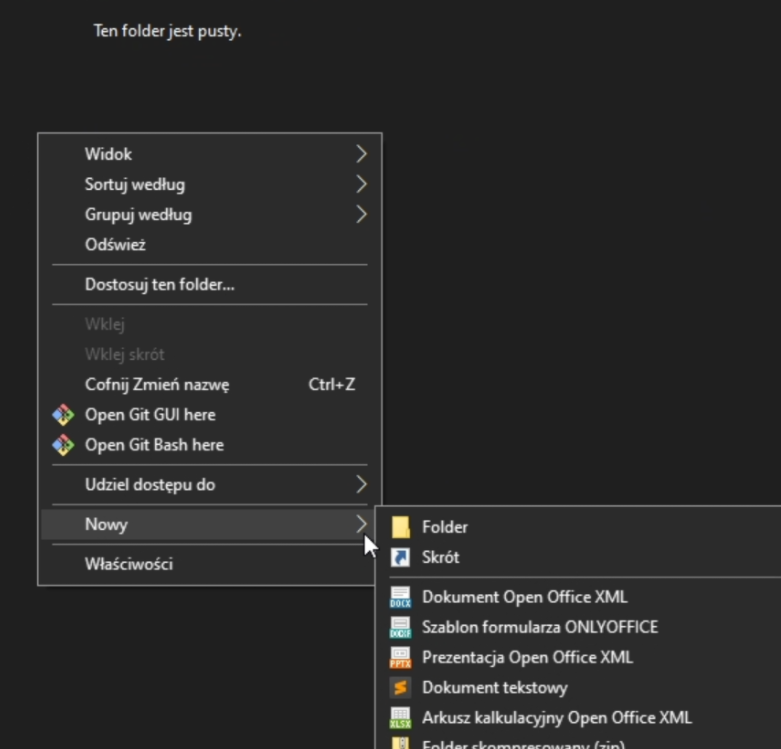
Przejdź do miejsca w którym chcesz utworzyć nowy folder do pracy, kliknij prawym i wybierz Nowy -> Folder

Na Windowsie 11 skorzystaj menadżer plików wygląda nieco inaczej - ma jednak identyczną opcję. Możesz kliknąć w lewym górnym rogu "Nowy" i wybrać tam folder.
Nazywając foldery sugeruję unikać polskich liter, znaków specjalnych (w tym spacji).
-
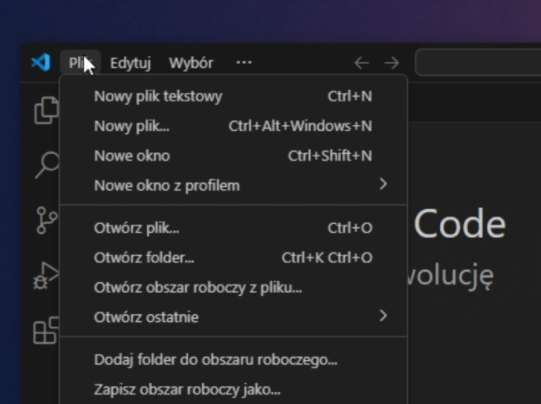
Uruchom nowe okno VSCode (Plik -> Nowe okno)

-
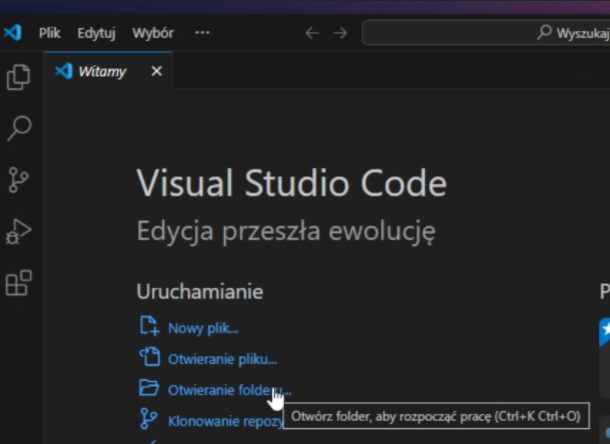
Wybierz "Otwieranie folderu"

-
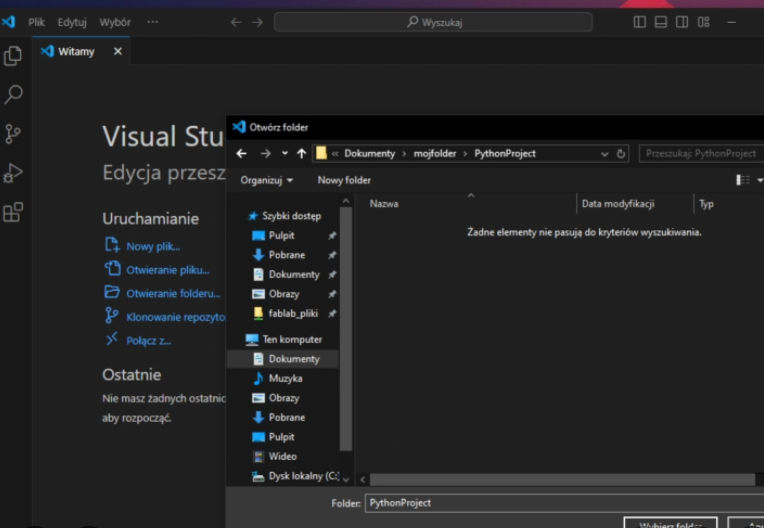
Odnajdź stworzony wcześniej folder i kliknij "Wybierz folder"

-
VSCode może zapytać czy ufasz autorom - wybierz "Tak"

-
Można już w tym nowym oknie pracować - tworzyć nowe pliki etc.

Obsługa plików w Pythonie
- służy do tego słowo
open
Sugerowane jest też dodanie słowa with tak aby plik był automatycznie domykany na koniec pracy (korzystamy w ten sposób z tzw. context managera).
Odczytywanie
with open("mojplik.txt") as moj_plik:
print(moj_plik.read())
Domyślnie Python otwiera pliki w trybie do odczytu ("r") - podczas pracy w nim można jedynie odczytać zawartość pliku, nie można nic dodać.
W powyższym przykładzie na wczytanym obiekcie jest użyta metoda .read() umożliwiająca odczytanie całej zawartości jako ciąg znaków (string).
Zapisywanie
Chcąc zapisać coś w pliku należy otworzyć go w trybie "w":
with open("mojplik.txt", "w") as moj_plik:
moj_plik.write("Nowa zawartość")
Parametr "w" jest dodawany do funkcji open, w nawiasach okrągłych, obok nazwy pliku, który chcemy otworzyć.
W powyższym przykładzie tekst "Nowa zawartość" zostanie zapisana do pliku mojplik.txt.
WAŻNE!!! - w tym trybie istniejąca zawartość pliku zostanie nadpisana(!).
Jeśli chcemy dopisać coś do końca pliku trzeba użyć trybu "a" (od append):
with open("mojplik.txt", "a") as moj_plik:
moj_plik.write("Nowa zawartość")
Tryb binarny i tryb tekstowy
Domyślnie Python traktuje otwarte pliki jako tekst. Czasami zachodzi jednak potrzeba otwarcia ich w trybie binarnym (np. przy większości formatów obrazków) - wystarczy dodać literkę "b" do trybu.
Pliki tekstowe to np. pliki .txt, .csv, .json, .xml, .py ... i wiele innych.
Binarne to większość obrazków (.jpg, .png...), pliki wykonywalne aplikacji (.exe)...
W tym kontekście mówimy o plikach tekstowych jako o plikach, które są w stanie odczytać ludzie (otwierając je np. w Notatniku czy innym edytorze tekstu).
Tabelka trybów
Poza trybem r służącym do odczytu,w do napisania i a do dopisania Python oferuje nam różne kombiancje trybów.
| tryb | opis |
|---|---|
r |
odczyt |
r+ |
odczyt i zapis, błąd jeśli plik nie istnieje |
rb |
odczyt w trybie binarnym |
rb+ |
odczyt i zapis w trybie binarnym, błąd gdy plik nie istnieje |
w |
zapis, nadpisuje zawartość, tworzy plik gdy nie istnieje |
w+ |
odczyt i zapis, nadpisuje zawartość, tworzy plik gdy nie istnieje |
wb |
zapis w trybie binarnym, nadpisuje zawartość, tworzy plik gdy nie istnieje |
wb+ |
odczyt zapis w trybie binarnym, nadpisuje zawartość, tworzy plik gdy nie istnieje |
a |
dopisanie zawartości, tworzy plik gdy nie istnieje |
a+ |
odczyt i dopisanie zawartości, tworzy plik gdy nie istnieje |
ab |
dopisanie w trybie binarnym, tworzy plik gdy nie istnieje |
ab+ |
odczyt i dopisanie w trybie binarnym, tworzy plik gdy nie istnieje |
Na początku dobrze jest pozostać przy podstawowych trybach - bo początkowo np. a+ i tym podobne mogą zaskakiwać (np. w a+ jak domyślnie odczytamy zawartość to nic nie dostaniemy - co wynika z tego, że w tym trybie znacznik położenie w pliku ustawiany jest na końcu zawartości).
Sprawdzenie czy plik istnieje
os.path.exists("sciezka_do_pliku")
Pliki JSON
- to jeden z najpopularniejszych formatów do przechowywania i wymiany danych
- budową przypomina nieco pythonowy słownik (ALE nie jest identyczny!!!)
- do obsługi plików w tym formacie wykorzystamy bibliotekę json
import json
Wczytanie JSON-a
- służy do tego funkcja
loadz modułujson
import json
with open("plik_z_danymi.json") as plik_json:
zawartosc = json.load(plik_json)
- wczyta to nam plik json, a następnie jego zawartość zamieni na odpowiedni obiekt pythonowy (tzw. deserializacja danych)
Zapis JSON-a
- służy do tego funkcja
dumpz modułujson - oczywiście chcąc zapisać należy użyć trybu
w
import json
dane = {"jabłka" : 4, "mango" : 3}
with open("plik_z_danymi.json", "w") as plik_json:
json.dump(dane, plik_json)
- zamieni to nam obiekt pythonowy
danena poprawnie skonstruowanego json-a i zapisze do pliku
Chcąc mieć ładniej sformatowany plik JSON można dodać jeszcze parametr indent do dump np.
import json
dane = {"jabłka" : 4, "mango" : 3}
with open("plik_z_danymi.json", "w") as plik_json:
json.dump(dane, plik_json, indent=4)
Kodowanie znaków
Domyślnie biblioteka json przy zapisie podmieni nam wszystkie "dziwne" znaki (np. polskie litery) tak aby całość dało się zapisać jako ascii.
Chcąc wymusić kodowanie utf8 należy:
- przy wczytywaniu
import json
with open("plik_z_danymi.json", encoding="utf8") as plik_json:
zawartosc = json.load(plik_json)
- przy zapisywaniu
import json
dane = {"jabłka" : 4, "mango" : 3}
with open("plik_z_danymi.json", "w", encoding="utf8") as plik_json:
json.dump(
dane,
plik_json,
indent=4,
sort_keys=True,
ensure_ascii=False,
)
CSV
- do obsługi plików csv służy biblioteka ... csv :D
import csv
with open("currency.csv", "r") as plik:
reader = csv.reader(plik)
print(reader)
for wiersz in reader:
print(wiersz)
Pandas
- kombajn do wszelkich danych statystycznych etc, w tym do obsługi plików wykorzystywanych w tej dziedzinie
- pandas natywnie operuje na tzw. ramkach danych (dataframes) i na nich wykonuje wszelkie operacje
- możemy użyć jej do deserializacji danych z plików csv, xlsx (po dodaniu biblioteki pyxml) i wielu innych
Np. otwarcie pliku csv z pomocą Pandas:
import pandas as pd
currency_dataframe = pd.read_csv("currency.csv")
print(currency_dataframe)
Przydatne funkcje do wczytywania plików z pomocą Pandas:
- read_excel (wymaga openpyxl)
- read_csv
- read_xml
- read_json
A na koniec krótkie przypomnienie:
Importowanie bibliotek
Aby wykorzystać jakąś bibliotekę, którą mamy zainstalowaną (pobraną na nasz komputer) należy użyć słowa import w kodzie pythonowym (najlepiej na początku):
import nazwa_biblioteki
Jeśli nazwa jest za długa możemy ją podmienić np.
import nazwa_biblioteki as nb
Instalacja bibliotek
Jeśli nie mamy biblioteki w systemie możemy ją pobrać np. wykorzystując narzędzie pip (w terminalu):
pip3 install nazwa_biblioteki
Własne funkcje
Funkcje
Funkcje to "czasowniki" w języku programowania. Czyli to nazwany blok kodu który wykonuje jakieś działania. Czasami w jego wyniku jest również zwracana jakaś wartość.
Do tej pory korzystaliśmy z funkcji dostarczonych nam przez Pythona (np . print), lub "wgranych" z biblioteki / modułu.
Pisząc własne programy już na tym etapie zetknęliśmy się z sytuacją gdy robiliśmy podobną rzecz wiele razy - zmieniały się np. tylko dane wejściowe np. modyfikowaliśmy jakiś adres w książce adresowej, gdzie zmieniało się tylko, który adres był modyfikowany.
Możemy taką funkcjonalność ;) zebrać w całość i udostępnić jako własną funkcję. Należy pamiętać, że Python odczytuje nasz kod linijka po linijce, z góry na dół - więc musimy stworzyć nasz "czasownik" przed jego użyciem (deklaracja funkcji musi być wcześniej w kodzie).
Własną funkcję deklarujemy używając słowa def.
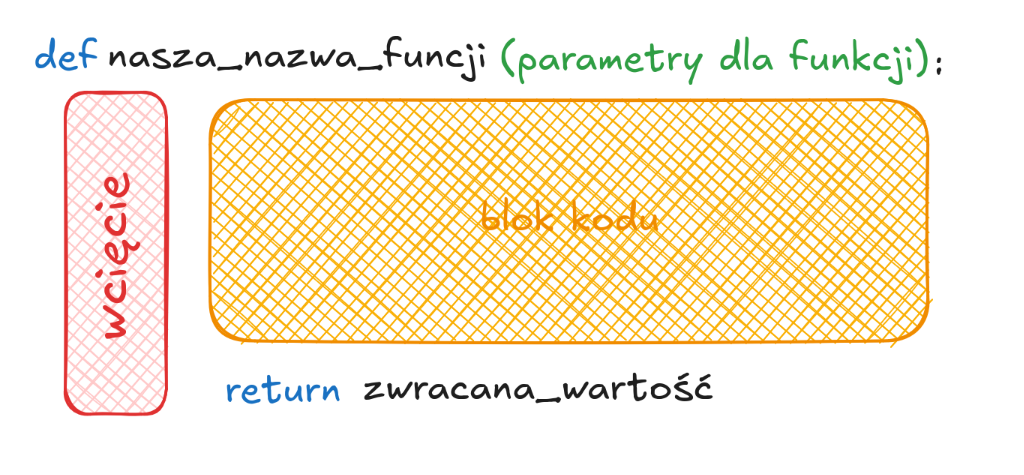
np.
def kwadrat(x:int) -> int:
wynik = x * x
return wynik
Zwróćcie uwagę na słowo return - wykorzystujemy je jeśli chcemy, żeby nasza funkcja poza wykonaniem jakiejś operacji zwróciła nam jakąś wartość (którą np. możemy przypisać do zmiennej). Bardzo dużo funkcji korzysta z tej opcji - np. funkcja sum zwraca nam sumę dwóch liczb, funkcja max zwraca nam największą wartość przechowywaną chociażby na liście itd.
Nie jest to jednak reguła - np. funkcja print wyświetla nam daną zawartość na ekranie, ale nie zwraca żadnej wartości.
Powyższy przykład zawiera nieco nieobowiązkowych rzeczy:
- informację o oczekiwanym typie danych parametru wykorzystywanego w funkcji (
x:int) - informację o zwracanym typie danych (
-> int)
Dodawanie tych informacji jest dobrą praktyką - ułatwia nam (i innym użytkownikom tego kodu) korzystanie z programu.
Ponadto dzięki nim narzędzia jakich używamy do pisania będą w stanie podpowiadać nam w przypadku popełnienia błędu związanego z użyciem nieprawidłowego typu.
Tak skonstruowana funkcje wykorzystujemy identycznie jak te wbudowane np.
def kwadrat(x:int) -> int:
wynik = x * x
return wynik
liczba = kwadrat(2)
print(liczba)
Powyższa kod wyświetli nam 4 gdyż jest to 2 podniesione do kwadratu (a właśnie to robi ta funkcja kwadrat).
Parametry pozycyjne
Paremetry do funkcji możemy przekazywać w kolejności ich zadeklarowania w sygnaturze funkcji np.
def wydrukuj_zmienne(a, b, c):
print("a to:", a)
print("b to:", b)
print("c to:", c)
wydrukuj_zmienne(1,2,3)
zakończy się wynikiem:
a to: 1
b to: 2
c to: 3
Czyli do a została przypisana 1, do b 2, a do c 3.
Jeśli przekazujemy parametry w ten sposób musimy znać ich kolejność w sygnaturze funkcji.
Parametry po kluczu
Możemy też skorzystać z innego wariantu:
def wydrukuj_zmienne(a, b, c):
print("a to:", a)
print("b to:", b)
print("c to:", c)
wydrukuj_zmienne(c=1,a=3,b=2)
co da:
a to: 3
b to: 2
c to: 1
W tym przypadku wywołując funkcję dokładnie podaliśmy do jakiej zmienne powinny przechowywać wskazane wartości.
Oznacza to trochę więcej pisania - ale jest mniejsze ryzyko popełnienia błędu. Ten wariant jest też bardzo przydatny przy bardziej rozbudowanych funkcjach, które mają masę możliwych parametrów - nie musimy zapamiętywać pozycji każdego z nich.
Zakres (scope)
"Wnętrze" funkcji jest odizolowane od reszty kodu. Ozancza to, że np. zmienna moja_zmienna zadaklarowana poza funkcją i identycznie nazwana zmienna wewnątrz funkcji to 2 RÓŻNE zmienne(!).
moja_zmienna = 55 # deklaruje zmienna
def moja_funkcja():
moja_zmienna = 1 # deklaruje zmienna wewnatrz funkcji
print(moja_zmienna)
moja_funkcja()
print(moja_zmienna)
# wynikeim będzie
# 1
# 55
# bo mimo identycznej nazwy
# zmienna wewnątrz funkcji operuje
# w innym zakresie (ma swoje wlasne nazwy)
GUI - Flet
Flet to biblioteka bazująca na Flutterze. Umożliwia tworzenie aplikacji z graficznym interfejsem użytkownika na urządzenia stacjonarne i mobilne w Pythonie. Dostarcza gotowe komponenty umożliwiające budowanie graficznych interfejsów użytkownika.
Ponieważ Flutter został stworzony w Google to interfejs stworzony z jego pomocą ma dość charakterystyczny wygląd wpisujący się w tzw. Material Design.
Dużą zaletą Flet-a jest duża ilość dobrze opisanych domyślnych ustawień - stworzone są one w taki sposób, że edytory kodu "podpowiadają" nam jakie mamy możliwości.
Instalacja Flet-a
pip3 install flet[all]
Ściągnie to wszystkie zależności i dodatkowe narzędzia używane podczas korzystania z frameworku Flet.
Przez framework rozumiemy szablon z zestawem komponentów wykorzystywanych do budowy aplikacji.
Bazowy schemat aplikacji
Aplikacje w Flet-ie można budować m.in. stosując podejście obiektowe.
W przypadku początkowych aplikacji można jednak podejść do tego prościej.
Można np. stworzyć funkcję opisującą okno programu, w niej z kolei będziemy deklarować wszystkie komponenty.
Takim komponentem może być przycisk, pole tekstowe itd.
Następnie należy dodać te zadeklarowane elementy do okna aplikacji (poprzez page.add).
Na samym końcu z kolei wywołamy naszą funkcję.
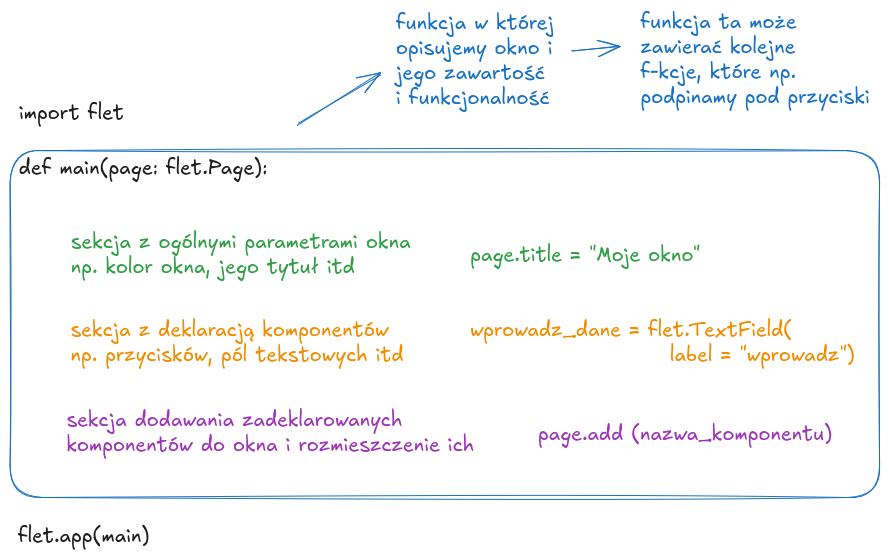
import flet
def main(page: flet.Page):
# Sekcja ogólnych ustawień okna aplikacji
page.title = "Tytul" # np. tytulu okna
# Sekcja deklaracji komponentów
# - czyli opisujemy np. jakie pola tekstowe,
# przyciski etc mają się znaleźć w oknie i jak
# mają one wyglądać.
tekst = flet.Text("Jakiś tekst.") # np.tekst
przycisk = flet.FilledButton("wciśnij mnie") # np. przycisk
# Sekcja umieszczania komponentów w oknie
# - czyli decydujemy jaki będzie ich układ,
# w jakiej kolejności się będą wyświetlać,
# gdzie zostaną umieszone
page.add(
tekst,
przycisk,
)
flet.app(main)
Czyli importujemy aplikację, tworzymy funkcję odpowiadającą za zbudowanie okna (czyli np. dodanie pól tekstowych, przycisków itd). Następnie funkcję tę wywołujemy za pomocą flet.app.
WAŻNE!!! Aplikację zbudowanej z framework-iem Flet lepiej uruchamiać przez flet run nazwapliku.py, a nie przez guzik "play" w VSCode czy python nazwapliku.py. Uruchomienie poprzez flet run powoduje, że nie musicie cały czas zamykać i otwierać okna po zaktualizowaniu aplikacji - zmiany wczytają się automatycznie.
Lista komponentów
Flet udostępnia całą masę flutterowych elementów - przycisków, pól do wpisywania danych, różnej maści menu itd.
Informacje na ich temat można znaleźć tutaj:
https://flet.dev/docs/controls
Najbardziej podstawowe komponenty to m.in.:
Text. Nieinteraktywny tekst wewnątrz oknaTextField. Pole do wprowadzania danychFilledButton. Przycisk wypełniony kolorem, z zaokrąglonymi bokami.
W praktyce
Przykładowa aplikacja wyświetlająca komunikat powitalny:
import flet
def strona_glowna(page: flet.Page):
# funkcja wykorzystywana w oknie, podpieta do przycisku
def przywitaj(_event):
if imie_pole.value:
imie = imie_pole.value
komunikat_tekst.value = f"Witaj {imie}!"
komunikat_tekst.update()
# sekcja ustawien okna
page.title = "Hello!"
# sekcja komponentów
imie_pole = flet.TextField(
label="Wprowadź imię:",
)
witaj_przycisk = flet.FilledButton(
text=" przywitaj ",
on_click=przywitaj,
style=flet.ButtonStyle(padding=10),
)
komunikat_tekst = flet.Text("")
# sekcja umieszczenia komponentów w oknie
page.add(
imie_pole,
witaj_przycisk,
komunikat_tekst,
)
flet.app(strona_glowna)
Warto zwrócić uwage na sposób podpięcia funkcji "przywitaj" do przycisku "witaj_przycisk" - czyli wciśnięcie przycisku spowoduje uruchomienie funkcji.
Wymaga to dodania "wyzwalacza" do przycisku - w tym wypadku "on_click" (gdyż chcemy aby funkcja była uruchamiana po wciśnięciu przycisku, są też inne wyzwalacze np. hover). Ponieważ chcemy żeby to Flet obsłużył uruchomienie funkcji to należy zwrócić uwagę, że po podaniu nazwy funkcji (w powyższym przykładzie przywitaj) NIE ma nawiasów okrągłych.
Drugą ciekawą rzeczą jest "tajemniczy" parametr _event dodawany do funkcji uruchaminej przez przycisk. Nazwę _event można zmienić, ale należy pamiętać, że musi się on pojawić jako pierwszy parametr funkcji wyzwalanej przez jakiś komponent graficzny aplikacji (przycisk etc).
GUI - TkInter
GUI
Graficzny interfejs użytkownika (GUI) umożliwia nam korzystanie z urządzeń przy pomocy ikon, przycisków, pasków i innych graficznych elementów.
Samodzielne przygotowanie tych komponentów i mechanizmów wymagałoby dużego nakładu pracy. Stąd też powstała cała gama "gotowców" z których można skorzystać w różnych języka programowania.
Do jednych z najpopularniejszych wariantów dostępnych w Pythonie należą:
-
TkInter
Ten zestaw narzędzi dostarczony jest razem z językiem Python. Umożliwia relatywnie łatwe rozpoczęcie tworzenia graficznych aplikacji.
Do jego głównych wad zalicza się wygląd - domyślnie aplikacje stworzone z TkInter nie wyglądają zbyt nowocześnie. Spowodowało to powstanie licznych modyfikacji oryginalnej biblioteki mających na celu poprawienie tego aspektu.
-
Qt (Pyside, PyQt)
Qt należy do najpopularniejszych frameworków GUI. Dostępny jest w większości języków programowania. W Pythonie dostępny jest z pomocą bibliotek Pyside i PyQt (ten pierwszy to oficjalny produkt firmy odpowiedzialnej za rozwój Qt).
Do bardziej wymagających projektów dostępny jest QtDesigner umożliwiający wizualne opracowywanie graficznego szablonu dla aplikacji.
-
GTK (PyGObject)
GTK wykorzystywany jest m.in. przez środowisko graficzne GNOME będący jednym z najpopularniejszych wyborów dla systemów opartych o Linux-a.
Zapewnia przyzwoity wygląd aplikacji, ale nie zawsze dobrze integrujący się z środowiskami innymi niż GNOME.
Istnieją nieoficjalne programy służące do projektowania okien dla GTK, takie jak Cambalanche.
-
Kivy
Framework wykorzystywany m.in. przy bardziej nietypowych interfejsach np. na urządzenia mobilne.
-
DearPyGUI
Zapewnia wsparcie wyświetlania z wykorzystaniem GPU, dzięki czemu w założeniu interakcja z aplikacją powinna być bardziej responsywna.
-
Flet
To stosunkowy nowy wariant, umożliwia wykorzystanie frameworku Flutter w Pythonie.
TkInter
Do zaimportowanie TkInter-a można użyć:
import tkinter as tk
- podmiana nazwy tkinter na tk to dość popularne podejście
Pierwszą czynnością zazwyczaj jest stworzenie podstawowego okna:
import tkinter as tk
okno = tk.Tk()
okno.title("Jakiś tytuł")
okno.mainloop()
Metoda mainloop odpowiada za uruchomienie głównej pętli odpowiedzialnej za wyświetlanie okna.
Podstawowe komponenty
Pełną listę komponentów można znaleźć tutaj:
https://docs.python.org/3/library/tkinter.html
Elementy interfejsu przypisujemy pod zmienne i przekazujemy odpowiednie parametry. Zazwyczaj pierwszy parametr wskazuje na to do którego elementu dany komponent należy (w najprostszym wariancie będzie to okno aplikacji).
Do podstawowych aplikacji można skoncentrować się na:
Label
- czyli prosta etykieta z tekstem
etykieta = tk.Label(rodzic_komponentu, inne_parametry)
np.
text_label = tk.Label(okno, text="jakis napis")
pic_label = tk.Label(okno, image=obrazek)
Button
- przycisk
przycisk = tk.Button(text="jakis napis", command=nazwa_funkcji)
Input
- pole do wpisywania zawartości
wprowadz = tk.Entry(width=80)
Frame
Gdy chcemy pogrupować jakieś elementy (przyciski, etykiety etc.) z pomocą przychodzi nam frame. Taka ramka staje się rodzicem pozostałych komponentów.
To kontener na inne komponenty.
import tkinter as tk
okno = tk.Tk()
okno.title("Jakiś tytuł")
ramka = tk.Frame(okno, padding = 10)
text_label = tk.Label(ramka, text="jakis napis")
wprowadz = tk.Entry(ramka, width=80)
okno.mainloop()
Rozmieszczanie komponentów
Jeśli spróbujecie powyższego kodu zobaczycie, że nie działa to jeszcze poprawnie. Wynika to z tego, że nie zadeklarowaliśmy w jaki sposób mają być rozmieszczone komponenty.
Dwie podstawowe metody to:
Pack
Rozmieszcza komponenty półautomatycznie w ramach rodzica zgodnie z przekazanymi parametrami. Mogą one być umieszczone poziomo lub pionowo zgodnie z wartością parametru side.
Parametry:
- side - określa położenie elementu (
top,bottom,left,right) - fill - określa czy element ma być rozciągnięty w daną stronę (
x,y,both) - padx, pady - odstępy na zewnątrz komponentu
- ipadx, ipady - odstępy wewnątrz komponentu
np.
import tkinter as tk
okno = tk.Tk()
okno.title("Jakiś tytuł")
ramka = tk.Frame(okno)
ramka.pack()
text_label = tk.Label(ramka, text="jakis napis")
text_label.pack(side="left")
przycisk = tk.Button(ramka, text="jakis napis")
przycisk.pack(side="right")
wprowadz = tk.Entry(okno, width=80)
wprowadz.pack()
okno.mainloop()
Grid
Elementy rozmieszczane są na siatce wierszy i kolumn (można to sobie wyobrazić jako umieszczenie ich w komórkach arkusza kalkulacyjnego.)
https://www.pythontutorial.net/tkinter/tkinter-grid/
W przypadku "rozciągnięcia" elementu na kilka komórek trzeba:
- ustawić colspan / rowspan
- ustawić kierunek wypełnienia (n, s, w, e, we, ns)
CustomTkInter
Myślę, że dało się zauważyć, że domyślny TkInter jest dość brzydki. Z pomocą przychodzą nam różne warianty tego modułu, które mają na celu poprawę tego aspektu.
Jeśli chodzi o składnię w większości wypadków jest niemal identyczna z podstawowym TkInter - należy jedynie podmienić nazwę modułu.
import tkinter as tk
import customtkinter as ctk
okno = ctk.CTk()
okno.title("Jakiś tytyuł")
okno.configure(padx=50, pady=50)
etykieta = ctk.CTkLabel(master=okno, text="Tekst etykiety")
etykieta.pack()
wprowadz = ctk.CTkEntry(master=okno, width=400)
wprowadz.pack()
# Do przycisku zazwyczaj dodaje się parametr
# command = nazwa_funkcji
# uruchamiajacy jakas funkcje po przyciśnięciu
przycisk = ctk.CTkButton(master=okno, text="Tekst przycisku")
przycisk.pack()
okno.mainloop()
Odnośniki
https://docs.python.org/3/library/tkinter.html
https://www.pythontutorial.net/tkinter/tkinter-grid/
John Elder, TKinter Widget Quick Reference Guide
Programowanie obiektowe - klasy
Klasy
Zazwyczaj chcemy żeby w naszym kodzie było możliwie mało powtórzeń, całość była jak najbardziej czytelna, a osoby korzystające z naszego programu miały jasne wytyczne czego nasz kod oczekuje.
Jednym z narzędzi w drodze do tego celu są klasy, będące fundamentem podejścia nazywanego programowaniem obiektowym.
Korzystając z tej metody staramy się modelować nasz kod w sposób nieco przypominający to jak zbieramy informacje o otaczającym nas świecie. Np. grupujemy gatunki w podobne kategorie. Pies domowy należy do rodziny psowatych, które z kolei należą do rzędu ssaków drapieżnych.
Mimo tego, że psy różnią się od siebie (ciężko pomylić jamnika z dobermanem) to mają one pewne cechy wspólne, które umożliwiają nam przypisanie ich do tego typu (gatunku).
Podobnie modelując aplikację staramy się znaleźć jakieś elementy wspólne obiektów, które tworzymy i na tej podstawie stworzyć typ grupujący je - służy on jako swego rodzaju szablon do stworzenia nowych obiektów.
Oprócz cech charakterystycznych (atrybutów) klasa zawiera też metody - czyli rzeczy, które dany obiekt może robić.
Jako przykład posłużmy się postacią do gry komputerowej rpg. Każda z nich będzie miała jakieś punkty życia, punkty magii, profesję itd. Żeby nie wymyślać tej struktury za każdym razem możemy zdefiniować odpowiednią klasę:
class PostacGracza:
def __init__(self, imie, profesja):
self.imie = imie
self.profesja = profesja
self.hp = 100
self.mana = 100
gracz1 = PostacGracza("Fizban", "mag")
gracz2 = PostacGracza("Taz", "łotrzyk")
Obie stworzone postaci (gracz1 i gracz2) zostały zrobione na podstawie tego samego szablonu (klasy PostacGracza), ale nie są identyczne - różnią się imieniem i profesją. Co więcej pozostałe ich atrybuty (hp i mana) mimo, że na start mają tę samą wartość są od siebie całkowicie niezależne (są to zupełnie osobne wartości). Czyli np. jeśli w trakcie gry Fizban otrzyma 30 obrażeń to będzie miał on 70 hp, podczas gdy Taz nadal będzie miał 100.
Klasa to nie obiekt
Ważne aby zdawać sobie sprawę, że ten przygotowany "szablon" nie jest równoznaczny z obiektem danego typu. W powyższym przykładzie PostacGracza to opis klasy, a gracz1 to juz obiekt klasy PostacGracza ("szablon wypełniony zawartością").
Na tej samej zasadzie np. definicja kota w encyklopedii nie jest naszym kotem Mruczkiem, który właśnie przeszkadza nam w pracy ;) .
Porównując klasy do np. szablonów ankiet, które dajemy komuś do wypełnienia to sam szablon byłby klasą, a uzupełniona, wypełniona przez kogoś ankieta byłaby obiektem.
Tworzenie klasy
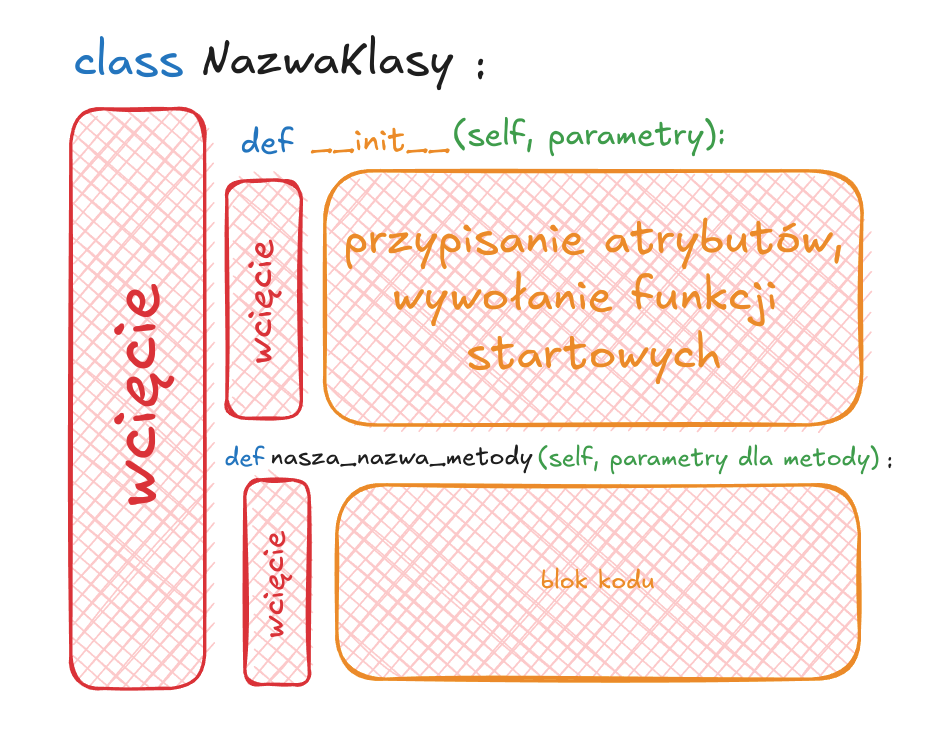
Metoda __init__
- to sekcja, która jest uruchamiana podczas tworzenia naszego obiektu na podstawie szablonu (klasy). Służy do przypisania obiektowi jego indywidualnych cech (w powyższym przykładzie będzie to np. wpisanie "Fizban" pod pole
imie), lub wykonanie jakiś czynności na starcie. Czyli mamy "szkielet" i w tym momencie wypełniamy go "mięsem". - sama definicja tej funkcji przestrzega wcześniejszych zasad np. warto opisywać typy jakie mają być przekazane
- bardzo istotne jest tutaj słowo
self. Wskazuje one, że przypisujemy indywidualne cechy do tego konkretnego obiektu, nie do całej klasy.
Wartości domyślne
Jeśli do któregoś atrybutu klasy często przypisujemy tę samą wartość możemy oszczędzić użytkownikowi jej wpisywania poprzez zadeklarowanie tej wartości domyślnej. W powyższej klasie mogłoby to wyglądać tak:
class PostacGracza:
def __init__(self, imie: str, profesja: str, hp: int = 100, mana: int = 100):
self.imie = imie
self.profesja = profesja
self.hp = hp
self.mana = mana
def powitaj(self):
print(f"Witaj {self.imie}.")
Tym samym chcąc stworzyć nową postać z domyślną wartością dla hp i many wystarczy wpisać:
gracz1 = PostacGracza("Taz", "łotrzyk")
Oczywiście chcąc dać np. magowi więcej punktów many możemy tę domyślną wartość napisać inną np.
gracz2 = PostacGracza("Fizban", "mag", mana=200)
Funkcje powiązane z klasą - metody
- możemy też dodać własne funkcje powiązane z daną klasą, czyli rzeczy, które dany obiekt może robić. Takie funkcje powiązane z klasą nazywamy metodami.
- jeśli chcemy, żeby metoda korzystała z jakiś atrybutów tego konkretnego obiektu (a powinna) ponownie ważne będzie słowo
self. Jeśli w metodzie nie skorzystamy z atrybutów danej klasy (a tym samym nie pojawi się słowo self wewnątrz niej) to jest dla nas wskazówka, że przypuszczalnie dana funkcja nie jest dobrym materiałem na metodę (i być może dobrze by było zadeklarować ją jako zupełnie osobną funkcję).
class PostacGracza:
def __init__(self, imie, profesja, hp =100, mana = 100):
self.imie = imie
self.profesja = profesja
self.hp = hp
self.mana = mana
def powitaj(self):
print(f"Witaj {self.imie}. Twoja profesja to {self.profesja} .")
W powyższym przykładzie mamy jedną metodę - powitanie. Wykorzystujemy je identycznie jak metody dostarczone razem z klasami dostarczonymi z Pythonem (czyli po nazwie zmiennej stawiamy kropkę, następnie wpisujemy nazwę metody i korzystamy z nawiasów okrągłych do uruchomienia i ew. przekazania jakiś parametrów). Np. chcąc stworzyć obiekt klasy PostacGracza i użyć metody powitaj należy np.
gracz1 = (imie="Fizban", profesja="mag")
gracz1.powitaj()
Dziedziczenie
W poyższym przykładzie z klasą PostacGracza jest zauważalny problem - profesja to nic innego jak pole tekstowe. Poza informacją o profesji nie wnosi nic nowego, nie rozszerza możliwości obiektu tej klasy. Czyli np. mag nie dostanie jakiś metod odpowiadających za rzucanie zaklęć, nie dostanie automatycznie większej ilości punktów magii itd.
Jednym z rozwiązań może być zastosowanie mechanizmu tzw. dziedziczenia. Tworzymy nową klasę (np. Mag) i oznaczamy, że... odziedziczy ona wszystkie cechy / metody innej (np. PostacGracza - tym samym PostacGracza jest w tym przykładzie rodzicem :D ). Następnie dodajemy nowe atrybuty / metody do tej nowej klasy - tym samym zwiększając dostępne możlwości.
Mogłoby to wyglądać np. tak:
class PostacGracza:
def __init__(self, imie, profesja, hp =100, mana = 100):
self.imie = imie
self.hp = hp
self.mana = mana
def powitaj(self):
print(f"Witaj {self.imie}.")
class Mag(PostacGracza):
def __init__(self, imie):
super().__init__(imie, hp=80, mana=200)
def rzuc_kule_ognia(self):
print("Rzucono kulę ognia!")
return 30
Klasa Mag rozszerza możliwości dostarczone przez PostacGracza o nową metodę - rzuc_kule_ognia oraz zmienia wartości przypisywane do atrybutów hp i mana.
super().__init__()
Funkcja ta służy do aktywowanie atrybutów klasy rodzica. Mówiąc inaczej - służy do uruchominie funkcji __init__ rodzica. Nie dodajemy w tym wypadku w niej słowa self - to jest przyjęte domyślnie.
Alternatywnie możemy zamiast funkcji super użyć nazwy klasy rodzica (np. PostacGracza)... ale w tym wypadku nie możemy pominąć słowa self.
class Mag(PostacGracza):
def __init__(self, imie):
PostacGracza().__init__(self, imie, hp=80, mana=200)
def rzuc_kule_ognia(self):
print("Rzucono kulę ognia!")
return 30
Z tego względu sugerowane jest użycie funkcji super.
Odnośniki
„3.12.5 Documentation”. Dostęp 18 sierpień 2024. https://docs.python.org/3/.
PyGameZero
Tworzenie gier wymaga zapanowania nad m.in. wyśweitlaniem obiektów na ekranie, wykrywaniem kolizji, obsługą urządzeń wejścia (np. gamepadów) itd. Stąd też powszechne jest korzystanie z gotowych "silników" i bibliotek zapewniających te rzeczy - tak, żeby programiści mogli się skoncentrować na samej logice gry.
PyGame Zero buduje na innej bibliotece - PyGame. Upraszcza ją jednak trochę np. dba o uruchamianie właściwej pętli z programem.
https://pygame-zero.readthedocs.io/
Chcąc skorzystać z bazowej biblioteki PyGame, bez ułatwień oferowanych przez PGZero, warto sięgnąć po PyGame CE - to nowsza odsłona tego projektu.
Instalacja
pip3 install pgzero
Szablon aplikacji
import pgzrun
from pygame import display
from pgzero import screen as pgzero_screen
from pgzero.builtins import keyboard
# rozmiar okna - pozniej wrzucimy to do osobnego pliku
WIDTH = 800
HEIGHT = 600
screen = pgzero_screen.Screen(display.set_mode((WIDTH, HEIGHT), 0))
# pygame uruchamia pętlę gry automatycznie
# ... ale potrzebuje do tego odpowiednio nazwanych funkcji.
# Korzystamy z funkcji update i draw.
def update():
# tu aktualizujemy stan obiektow
pass
def draw():
# tu je rysujemy
pass
# wywołanie pętli gry
pgzrun.go()
W powyższym szablonie została nieco rozbudowana sekcja importów - tak, aby edytory kodu nie "marudziły" podczas tworzenia aplikacji (biblioteka niestety jest napisana w sposób, który niezbyt dobrze współgra z tego typu narzędziami).
Folder images i sounds
W folderze z projektem dobrze jest stworzyć podfoldery sounds i images. To miejsca w których domyślnie PGZero będzie szukać dźwięków i obrazków.
Niezbędne funkcje i klasy
Funkcja update()
Jeśli będziemy mieli jakieś obiekty, których stan się będzie zmieniał niezbędna będzie nam funkcja update(). W nią wrzucimy takie rzeczy jak np. sterowanie, wykrywanie kolizji etc. - czyli wszystko co zmienia stan obiektu (np. dodaje / odejmuje jakąś wartość do atrybutu odopowiadającego za jego położenie na ekranie).
Funkcja draw()
W kodzie na pewno będziemy potrzebowali stworzyć funkcję draw. Odpowiada ona rysowanie obiektów.
Klasa Actor
Wszędzie tam gdzie będą obiekty wchodzące z sobą w interakcje przyda nam się klasa Actor. Zapewni nam obsługę kolizji, zadba, że odpowiedni obrazek znajdzie się we właściwym miejscu itd.
Metoda .draw.text z screen
Służy do obsługi tekstu w grze.
Streamlit
Streamlit to framework (platforma, szkielet do budowy aplikacji) do tworzenie aplikacji web-owych z wykorzystaniem języka Python. Nie wymaga znajomości HTML-a, Javascript-u, czy CSS-a.
Powstał z myślą głównie o zastosowaniach w analizie danych (tworzenie różnej maści dashboardów etc). Jednak społeczność jego użytkowników często stosuje go do zastosowań mocno odbiegających od tej tematyki.
Instalacja i dodanie do programu
Framework ten możemy zainstalować wykorzystując menadżera pakietów pip:
pip3 install streamlit
Importujemy go do aplikacji w standardowy sposób, poprzez import. Przyjęło się wykorzystywać tę bibliotekę pod nazwą st (stąd pojawiają się po import dodatkowe słowa as st):
import streamlit as st
st.write("Hello World!")
Uruchamianie aplikacji
Aplikacje stworzone z Streamlit-em NIE SĄ uruchamiane w "normalny" sposób (czyli np. poprzez python nazwaprogramu.py czy guzik play w VSCode). Zamiast tego musimy:
streamlit run nazwaprogramu.py
Dzięki temu uruchamiany jest serwer www umożliwiający nam oglądanie naszej aplikacji w przeglądarce i pozostała funkcjonalność niezbędna Streamlit-owi.
Podstawowe komponenty Streamlit-a
Zachęcam do przejrzenia oficjalnej dokumentacji dostępnej pod:
Zawiera ona bardzo dobre przykłady dla wszystkich dostępnych komponentów.
Tytuł okna
st.set_page_config(page_title="Jakiś tytuł")
Komponenty "tekstowe"
st.write("tekst")
- jeden z najbardziej uniwersalnych komponentów umożliwia wyświetlanie tekstu, markdownu, ramek danych, obrazków. Komponent ten rozpoznaje też tekst zapisany w markdown-ie, dzięki czemu może oszczędzić nam korzystania z kompomentów takich jak title, header, czy subheader.
st.title("tekst")
- umożliwia stworzenie tytułu (H1)
st.header("tekst")
- nagłówek
- można dodać parametr
divider, który doda podkreślenie
Komponenty do wprowadzania / wyboru danych
st.text_input()
- pole do wprowadzania danych
st.slider()
- suwak
- możemy dodać min_value i max_value, które ograniczą nam zakres do wyboru
st.checkbox()
- pole do zaznaczenia "ptaszkiem"
st.multiselect()
- umożliwia wybrania kilka elementów z jakiegoś zakresu danych
Wykresy
st.bar_chart()
- wykres słupkowy
st.line_chart()
- wykres liniowy
st.scatter_chart
- wykres punktowy
Formularze
Wciśnięcie / wybranie jakiegokolwiek elementu na stronie zbudowanej z pomocą Streamlit-a spowoduje jej całkowite przeładowanie.
Wyjątkiem jest formularz - jego zawartość jest przeładowywana jedynie po wciśnięciu odpowiedniego przycisku.
import streamlit as st
with st.form("Jakiś formularz"):
st.write("Wewnątrz formularza")
slider_val = st.slider("Suwak")
checkbox_val = st.checkbox("Checkbox")
# Formularz powinien mieć przycisk do wysłania.
submitted = st.form_submit_button("Wyślij")
if submitted:
st.write("Suwak: ", slider_val, "Checkbox: ", checkbox_val)
st.write("Poza formularzem")
Przechowywanie stanu zmiennych
Co w przypadku gdy nie korzystamy z formularza i mamy potrzebę przechowania stanu jakiejś zmiennej, tak żeby nie została ona odświeżona po wciśnięciu przycisku lub wykonaniu innej akcji?
W tym celu udostępnia specjalną zmienną session state:
https://docs.streamlit.io/develop/api-reference/caching-and-state/st.session_state
Odnośniki
„Streamlit Documentation”. Dostęp 18 sierpień 2024. https://docs.streamlit.io/.
API
- skodyfikowany, ustalony sposób komunikacji między dwiema lub więcej aplikacjami (Application Programming Interface).
To rodzaj umowy - "jeśli zadasz pytanie w ten sposób, dostaniesz ode mnie odpowiedź w takim formacie". Tę spisaną umowę możemy potraktować jako rodzaj instrukcji umożliwiającej uzyskanie potrzebnych nam danych z zewnętrznej aplikacji.
Tworzą je programiści / architekci tworzący daną aplikację.
REST API
To zestaw wytycznych jak konstruować API w pewien określony sposób. Zawiera opis funkcji jakie API powinna realizować (GET, PUT, DELETE...) i sposób realizacji (np. brak przechowywania stanu pomiędzy zapytaniami, zapytania o ten sam zasób powinny wyglądać tak samo).
REST (Representational State Transfer) nie jest standardem / protokołem - to zestaw "luźnych" wytycznych np. nie ustala w jakim formacie będą dostarczane dane, może to być JSON, XML itd. (chociaż najczęściej spotyka się JSON-a).
Jeśli szukacie czegoś "sztywniejszego" należy sięgnąć po alternatywy np. SOAP (tam np. mamy sprecyzowane, że dane mają być wymieniane poprzez XML). Jednak ta elastyczność REST-a jest jednym z fundamentów sukcesu tego podejścia.
Aplikacje spełniające wymogi REST nazywane są RESTful.
Aby odczytać REST-owe API wysyłamy komunikat GET na odpowiedni adres pod którym jest przechowywany poszukiwany zasób (można to zrobić nawet w przeglądarce).
Jeśli chcemy uzyskać jakiś bardziej sprecyzowany zakres danych aplikacje je udostępniające zazwyczaj dają nam przynajmniej jedną z możliwości:
- Inny adres dający nam te sprecyzowane dane
- Parametry, które dodajemy do adresu lub w treści zapytania
Aby ułatwić testowanie / przeglądanie API powstała cała grupa aplikacji takich jak Postman , Insomnia, Hoppscotch itd.
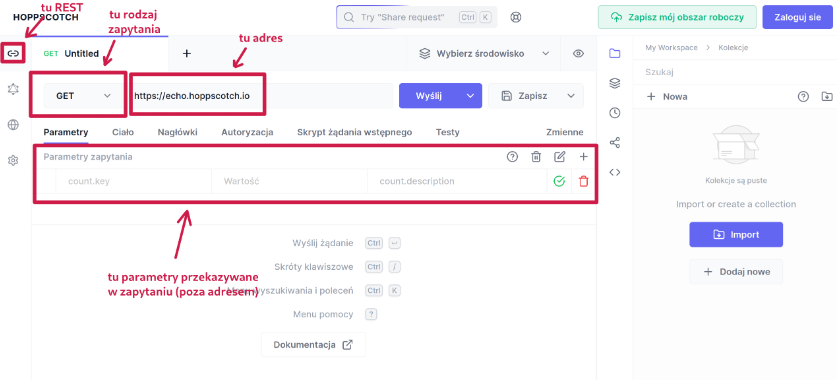
Hoppscotch.
To narzędzie umożliwiające nam testowanie i konstruowanie zapytań do API - bardzo ułatwia pracę, umożliwia przygotowanie działających zapytań przed ich implementacją w aplikacji.
- dostępny pod adresem https://hoppscotch.io/

CRUD
W kontekście API często pojawia się termin CRUD jako aplikacji realizującej 4 podstawowe funkcje:
- Create (put/post - tworzenie)
- Read (get - odczyt)
- Update (post/put/patch - aktualizuj / modyfikuj)
- Delete (delete - usuń)
Python - requests
- służy do komunikacji z wykorzystaniem protokołu HTTP/HTTPS (czyli tego wykorzystywanego na stronach www)
https://requests.readthedocs.io/en/latest/
Jak zwykle zaczynamy od zaimportowania, po czym od razu możemy przystąpić do wysyłania zapytań - np. typu GET (czyli pobierz).
import requests
odpowiedz = requests.get("https://api.frankfurter.app/latest")
Zwróci nam to obiekt typu Response. Jak go zdekodować?
Jeśli dostaliśmy JSON-a to np. tak:
odczytana = odpowiedz.json()
Jeśli chcemy po prostu odczytać odpowiedz jako tekst to Response ma atrybut .text.
Jeśli zachodzi potrzeba dodania jakiś parametrów wystarczy np. przekazać odpowiednio skonstruowany słownik.
parametry = {"key1" : "value1", "key2" : "value2"}
odpowiedz = requests.get("https://api.frankfurter.app/latest", params = parametry)
Podobnie jeśli chcemy dodać coś w nagłówku / body zapytania:
naglowek = {"user-agent" : "my-app/0.0.1"}
odpowiedz = requests.get("https://api.frankfurter.app/latest", headers = naglowek)
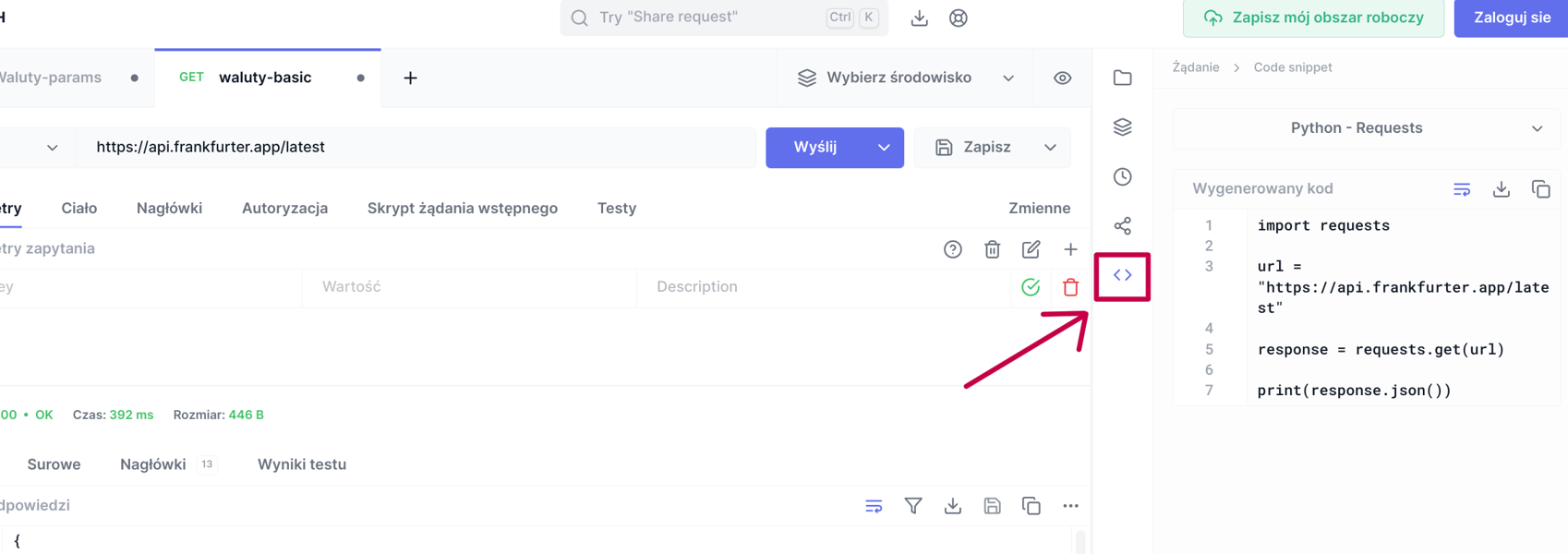
Hoppscotch - "gotowce"
Korzystając z narzędzi do testowania API możemy wspomóc się gotowym, wygenerowanym przez nie kodem:
Odnośniki
„3.12.5 Documentation”. Dostęp 18 sierpień 2024. https://docs.python.org/3/.
Amazon Web Services, Inc. „What Is an API? - Application Programming Interface Explained - AWS”. Dostęp 15 wrzesień 2024. https://aws.amazon.com/what-is/api/.
„API”. W Wikipedia, 13 wrzesień 2024. https://en.wikipedia.org/w/index.php?title=API&oldid=1245469139.
Dale, Kyran. Data Visualization with Python and Javascript: Scrape, Clean, Explore & Transform Your Data. Beijing Boston Farnham Sebastopol Tokyo, 2016.
„Hoppscotch • Open Source API Development Ecosystem”. Dostęp 15 wrzesień 2024. https://hoppscotch.io/.
„What Is a REST API?” Dostęp 15 wrzesień 2024. https://www.redhat.com/en/topics/api/what-is-a-rest-api.
„What Is a REST API? | IBM”, 19 październik 2021. https://www.ibm.com/topics/rest-apis.
Zagadnienie zaawansowane
Programowanie funkcyjne w Pythonie.
https://pl.wikipedia.org/wiki/Programowanie_funkcyjne
Podejście do programowanie (styl) który kładzie nacisk na tworzenie funkcji zamiast na zmianę stanu zmiennych. Koncetruje się bardziej na tym CO ma się wydarzyć a nie jak.
Python zazwyczaj nie jest pierwszym wyborem jeśli chodzi o ten styl pisania kodu - chociażby przez to, ze właściwie wszystko możemy w nim modyfikować, podczas gdy w programowaniu funkcyjnym raczej stawia się na niemodyfikowalność stanu (immutability).
Python jednak daje trochę możliwości, które umożlwiają pozanie tego podejścia np. to, że funkcje w nim możemy traktować jako wartości (first class functions - o czym często nieświadomie można przekonać się zaczynając przygodę z Pythonem i zapminając o dodaniu "()" po nazwie funkcji), to, że możemy zwracać funkcje jako wartości (higher order functions).
Lambda
- to (zazwyczaj) krótkie funkcje, którym nie przydzielamy nazwy. Najczęściej używane gdy w kodzie potrzebujemy na "juz i teraz" jakąś krótką funkcję (mieszczącą się np. w jednej linijce).
x = lambda a : a + 10
print(x(5))
def myfunc(n):
return lambda a : a * n
mydoubler = myfunc(2)
print(mydoubler(11))
mytripler = myfunc(3)
print(mytripler(11))
Map
- umożliwia zastosowanie jakiejś funkcji na elementach kolekcji (czyli możemy zastąpić pętle). Zwraca iterator - więc jeśli chcemy finalnie mieć inny typ (np. listę) to musimy dokonać konwersji.
def kwadrat(x):
return x * x
nums = [1, 2, 3, 4, 5]
do_kwadratu = map(kwadrat, nums)
print(list(do_kwadratu))
Filter
- umożliwia zastosowanie jakiejś funkcji na kolekcji celem odfiltrowania wartości. Czyli zwraca nam jedynie te wartości na których wykonana funkcja zwróciła
True.
Reduce
- akumuluje wartości zebrane po wykonaniu funkcji na kolekcji
import functools
def silnia(n):
return functools.reduce(lambda x, y: x * y, range(1, n + 1))